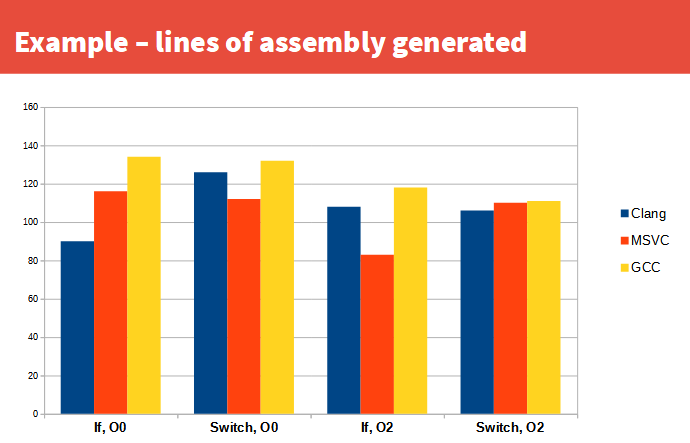
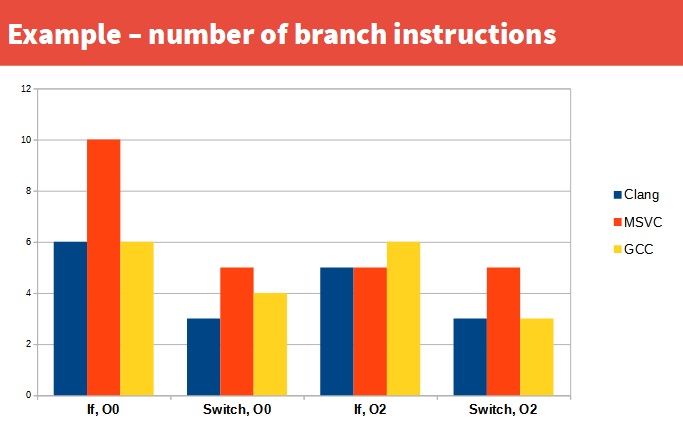
I didn't particularly want to do this as it means plf:: packages are no longer just a single header, but it became unavoidable in the context of developing plf::bitset_stack(s), as there's at least 4 of those, possibly 5.
Basically I've had to split out all the compiler feature macros + all the common shared tools into a separate file/repo, plf_tools, which is fine in the sense that now there's only one file to update across all containers/etc - including their test suites, which originally typically included a carbon copy of the compiler feature macros in order to test under C++03/11/etc. So there's some space saving, but mainly it's less error-prone to update these things.
I'm going to include the plf_tools.h in all plf::container repos, just so people don't have to run around trying to find this new-fangled plf_tools repo - which is going to make it annoying for me, in terms of updating plf_tools, but better for end user. In addition there's a plf_tools_undef.h, which gets (conditionally) used at the end of containers/etc to undef the compiler feature macros. I've actually made this less problematic in terms of using multiple plf::containers now - basically there's some macro-guarding such that if you make a plf::list<plf::colony<int>>, the colony isn't going to undefine the macros before the plf::list does - and if anything plf::-related encapsulates the plf::list, the plf::list won't undefine the macros etc etc etc.
So overall this is a forward step, though it does add a couple of additional files to the mix for most users. The only units I didn't make use plf_tools.h were plf::rand and plf::nanotimer, since they're only using the PLF_NOEXCEPT macro, and it seemed wasteful to include everything else when it greatly dwarfs the size of those .h's. So their macros have just been slightly redefined to not mess with the plf_tools macros.
More news to come - particularly since I've been working on a new version of colony with Slaven Falandys.
I found out about boost::hub 2 weeks ago through a friend. To be clear I'm not against hub, nor it being in Boost - I'm for it. Also, I've been talking with the author, Joaquin, since then, and we've come to some interesting arguments and discussions, in which we've both learned stuff, while still disagreeing on some topics. I will state that the container does not live up to some of the community talk I've heard. Myself and Joaquin have had some disagreements over aspects of his benchmarking, while I acknowledge that they show the general trends - as an example, benchmarking different containers within the same executable in my experience can lead to the compiler preferentially inline one container's functions at the expense of anothers. But I think the main gap/problem in the benchmarks is not benchmarking the same container instance over a long period of time as elements are erased, inserted, and iterated over. Specifically iteration speed when gaps between non-erased elements become larger and empty blocks stack up was not measured. This, I think has resulted in some of the claims in the community. Though it can be faster in the right scenarios - typically, very high ratios of insert/erase compared to iterations over the container.
So I ran my benchmarks with plf::hive vs boost::hub. Here are the results for GCC, MSVC and Clang. A few key differences between mine & Joaquins approaches: they warm up the cache before measurement, take many container-size sample points rather than just a few, and include a benchmark which inadvertently shows the effects of a small fixed block size on get_iterator (referencer). The most relevant benchmarks are Unordered Modification, and Referencer. The first measures a container's speed over time as elements are erased, inserted and iterated over. Different graphs show results with different ratios of iteration to insertion/erasure. In general across compilers you will find that hive is faster for most ratios, while hub is only faster for very high amounts of insert/erase - specifically, either 5% or 10% of all elements being inserted/erased for every iteration pass over all elements. There is significant difference between the compilers in terms of how well they optimize each container's code: in MSVC hive is quite a bit faster than hub except for very-high insert/erase ratios, in clang it is much slower, in GCC it is in between.
The second graphs you should pay attention to, the Referencer benchmarks, show the speed of multiple instances of the same container, housing different types, which reference each other, in the vague structure of a game engine. 'Entity' elements are inserted and erased at various ratios per-iteration, as with the Unordered Modification benchmarks. When these entities are erased/inserted, their corresponding elements in the other container instances are also erased/inserted. All links between containers are stored as pointers, using get_iterator as needed when erasures occur. This has been found to be faster than storing the iterators due to their larger size (3 or 2 words as opposed to 1). This benchmark also gives an indication as to performance under real-world scenarios when a pre-existing engine or framework requires storing pointers to elements.
What you'll find for the latter, is because there is less focus on iteration and more on insert/erase and accessing elements via pointers, initially hub is faster for small numbers of elements, but as the numbers of elements increases, the poor performance of hub's get_iterator (which, to be fair, would be the same performance hive would have if a user constrained the block sizes to min = 64, max = 64) takes over. For this reason hub is up to 32x slower than hive on this benchmark.
I seldom pay attention to micro-benchmarks for this style of container (I have been sent several over the years) because they don't tell a good story about what container performance looks like over time as erasure gaps increase and change. However in terms of micro-benchmarks plf::hive seems to be generally faster for iteration, and generally slower for insertion and erasure, but there is a lot of variability here based on element size and compiler. Larger element sizes, and larger numbers of elements, tend to work out better for hive, while smaller ones work out better for hub.
Lastly, sort speeds are largely better for hub, with the exception of very large element sizes. Both of us have work to do there :/
Obviously hub wouldn't exist without the std::hive specification, because it implements most of it's functionality, albeit with a slightly approach to the plf implementation. My personal perspective is that it is a slight fork of the hive spec, with some extensions. There are only 2 fundamental differences (fixed block sizes are allowed in hives) between the std::hive specification and hub: lack of 3-way-comparable iterators, which is an optimisation in terms of hub performance as it reduces the amount of per-block metadata needed - which is more relevant for hub since it has comparitively-many blocks compared to hive. Re: 3-way-comparable iterators in std::hive, these are useful when you're trying to gauge when a specific iterator has gone past another, for example when iterating over a sorted hive in non-1 steps. The second, trim_capacity() having a time complexity which is linear in the number of all blocks, not just reserved blocks, is an outgrowth of a container decision which optimizes insert/erase but pessimizes iteration performance over time.
I'll explain: in std::hive it is an expectation that the implementor will have a separate list of blocks-with-erasures, and blocks-which-are-empty. This enables optimal iteration speed, as by default you want fewer erasures in a given block, because this increases cache locality during iteration. So you want to be inserted new elements into erased element locations when you can, in order to fill up those holes. Hub's strategy is to have a single list for both empty blocks and blocks-with-erasures, which understandably increases insert/erase speed, as there's fewer checks to do, but it means insertion can't always fill up the holes in the blocks-with-erasures first.
Fixing the latter would also mean that trim_capacity would have time complexity complaint with the std::hive specification. Which would bring us down to 1 fundamental difference between hub and the hive specification [UPDATE: Joaquin has fixed this, and the trim_capacity time complexity is the same as hive's]. The other differences are primarily additional functionality, most notably visitation. I like visitation! Good concept - basically it's for-each iteration, but with hardware-based prefetching. It only works when the container is doing it, because the container knows when it's going over to a new block during iteration. It can be applied to any semi-contiguous container - deque, hive, colony, plf::list, etc etc etc. It's not specific to hub. I may implement it in colony at a later point and/or as a for_each overload for std::hive if it's possible.
But it is somewhat limited/limiting as to how you can use it - basically it's good when you want to take one process, and apply it to a range within the container or every element in the container ie. same as for_each. And it's incompatible with anything using iterators, ie. most of the standard library including ranges. So generally hive will be faster when it comes to standard library use - which is what it's part of.
Finally we get to memory usage - it's no surprise that hub can have significantly lower memory usage than plf::hive, given it's use of a bitfield for skipping elements as opposed to plf::hive's (typically) 16-bit skipfield. There is a large variance here based on container size, but hub can be between 50% and 96% smaller than plf::hive. Obviously the larger the element type, the smaller this difference becomes. But this is applicable only to my implementation of std::hive, not std::hive implementations in general. I am (since august last year) working on another memory-scarce implementation of plf::hive with a friend which limits the skipfield to ~1.2bits on average, while remaining within the std::hive specification. It's not clear what the performance characteristics will be compared to plf::hive at this point, but I hope better, not worse. We'll see.
So in summary, there's a real mix of performance results, but seeing innovation is great - I want more implementations, more experimentation, and potentially-better implementations than my own. As I said in my plf::list speech, it's good if people just go out there and do their own thing, regardless of whether or not what they're doing is actually unique - because often they can end up discovering things that other people with more pre-existing knowledge might not. Hub clearly has areas where it outperforms plf::hive, and for the moment has much-superior memory usage. It's best if people do their own benchmarking, in their own use-case, and see which is a better fit. Because neither myself nor Joaquin's benches cover all scenarios, compilers, and types.
Breaking update. Decided to bring bitset & bitsetb in line with the future bitset_stack containers - that is to say, the next_one/prev_one/next_zero/prev_zero functions no longer search from after/before the supplied index - they search from the supplied index now. The naming was always a little ambiguous, but I decided to go this direction. Also probably improved the code somewhat. BTW those containers have a count_range function now. Just so you know.
It's not that it's flawed, it's that there's such a limited subset of the language that can be used with it. I'd like to like it, but thinking in constexpr terms makes you limit how you think about code to that subset. No reinterpret_cast, no funny tricks or UB, no fun, basically. There's so much performance you lose from thinking about things in this way. Again, not a fault of the concept, and I see why implementors want to do this slowly. We're not prepared for the full consequences of a buffer-overflowing memory overwrite in realtime code, let alone compile time. I can see it working with the whole of the language, it just requires a ton of implementor effort - namely, to provide some kind of debug interface for code that executes while the compiler is running. That's a mean feat, and I don't blame anybody for not wanting to do it.
But, it seriously makes you rethink the validity of the venture. Once the peeps say 'constexpr everything' it gets a little reductive. Suddenly we're not talking C++, we're talking C+ at best. I'd rather have my brain un-guard-railed. No fun otherwise.
I like Herb, you don't get to be chair of WG21 for over a decade without being a sufficiently nice guy - and he is. I'd count him a friend if chairs were really allowed to have friends/preferences. His perspectives on C++ demand/growth/iteration are worthwhile to read, here. The doomsaying about C++ often ignores the very real gap that it and Rust fill, which no other languages sufficiently meet - high performance, low latency, minimal overhead.
Having said that the appendix to the article contains some opinions I find disquieting. The techno-positivism about AI is misplaced - there are no upsides, outside of programmer and medical work (and the former is debatable). It is destroying academia by allowing students to avoid writing and thinking for themselves, destroying communication by allowing people to avoid displaying themselves in honest and authentic ways, destroying music (~50000 AI-generated songs are presently being uploaded to Spotify per-day) by whitewashing the landscape with mediocre slop, and has already begun destroying the careers of visual artists by making them inconvenient. It is, of course, also destroying the internet and making electricity more expensive for everybody.
Anyone who argues otherwise either has skin in the game on the wrong side, or has no skin in the game at all. It reminds me in some ways of the misplaced passivity around piracy in the 00's, where people would try and convince me that copying 12 albums onto a USB stick within 1 minute was the same as spending an hour copying 1 album onto a cassette tape in the 80's. It wasn't of course, and it destroyed what was good about the music industry. I'm a bit tired of holding my tongue or being laissez-faire about it. Either you oppose it, or you're on the wrong side of the fence.
Recommended:
Overall I agree with the video. The problems it portrays, while hyperbolised, are real and accurately described - for the most part. The language is iterated upon by C++ language experts, who are not always external domain experts or good computer scientists. Don't get me wrong - there are some very smart people on the committee and people who're involved heavily in their given domains, but C++ has become so complex now that it requires extensive domain knowledge *as a field itself*. So you actually need those C++ experts to navigate it. Hence there can be a somewhat incestuous element at play. What the video does right is exposing to C++ users the abrupt and stark comparison between it and other languages, rather than looking at C++ in a vacuum. It assumes the viewer is not someone with a lot of experience with languages outside than C++, and is possibly correct in terms of the majority of people who will be viewing the video; and I think it does the world a service, in that way.
But here's some of the things the video gets wrong:
With all that being said, I acknowledge that the C++ infrastructure is horrible; his main point. I get around that personally by:
But I use this language for a reason. Things I like about C++:
Subjective appreciations and depreciations aside, my expectation is that over time many safety-critical infrastructural things will be replaced with Rust code or similar. However anything where performance is paramount and safety secondary, will stick with C++, or something like it. This may include gamedev, financial stuff, and physics simulation, etcetera. I was personally surprised the video didn't mention Jai, but to be honest that language might as well be dead (given that it's been in closed development for ~10 years with no public beta).
But also... worst?? Has he seen Perl? (or Brainf***?) There are worse, for sure.
Managed to improve the algorithm for reserve so that, instead of allocating too many elements when the remainder of requested_capacity % block_capacity.max is smaller than block_capacity.min. In most cases the resultant capacity should be much closer to the requested amount, if not exactly the same. For example, before if you had an empty colony/hive with min/max block capacities of 50/70, and you called reserve(150), it would allocate 190 (2 x max + 1 min). Now it allocates 150 (3 x 50). The result is actually microscopically faster due to the lower amount of allocation.
In addition some exceptional scenarios - pointed out by bloomberg - have been addressed in reserve(). Specifically when calling reserve(n) when n <= max_size() would bring capacity over max_size() due to the prior capacity and block capacity limits. And I found a weird bug in range fill insert/construction that I'm not even sure how it got there :/
next_one(index), prev_one(index), next_zero(index) and prev_zero(index) have been supplied for bitset/bitsetb/bitsetc - each adds an optimized way to return the next/prev zero/one in the bitset, before/after the supplied index number. The same speedups expected from first_zero/etc are also in these functions. The plf::bitset ones are noexcept and all are constexpr-capable.
I wrote a paper which goes into this in depth. For a particular application I was thinking about the fastest way to calculate the first 1 in any series of bits. The linear response is of course, scan from the front of the row of bits, and find the first one. The secondary way is to tackle it at the word level - that is, for a 64-bit platform, scan the words containing the bits until a non-zero word is found, then go into that word and use either std::countr_zero or manual counting to find the first 1 within that word quickly. This is how plf::bitset does it.
This is all well and good, until you start to run into very large bitsets. At that point, even the word-level scan takes a long time. But what if you use another, secondary bitset, on top of that bitset? So, taking that first set of words, notate in a secondary bitset the words which are non-zero. That is, for every 64 bits (assuming a bitset using 64-bit integers), you get 1 bit in the secondary bitset. 0 represents a zero word in the first layer, 1 represents a non-zero word. Now you can scan this 2nd bitset layer on a word-level - with every word representing 4096 of the first bitset's bits - until you find a non-zero word on that layer, and then use std::countr_zero to find the first non-zero word in the first bitset, then use std::countr_zero on that word to find the first bit.
Now the fun thing about this is that you can scale it up as much as you want. For the 2nd bitset, you're effectively scanning 4096 1st-layer bits per word - for a 3rd layer of bitset, you're scanning 262144 1st-layer bits per word - for a 4th layer 16777216 bits, and so on. What this means is that for a 1073741824 length bitset, you could, with a 4-layer system, find the first non-zero bit in the bitset within 64 comparisons plus 4 calls to std::countr_zero (usually maps to a CPU intrinsic).
Or you can tweak it and say that at the 2nd layer each bit represents 4 words - so you're scanning 16384 bits per 2nd-layer word. There's a load of room for manipulation. The (not so) tricky part is updating the layers - basically if going from zero to non-zero or vice-versa at the word level on any given layer, this has to be updated in the layer above - and then up through the rest of the layers as necessary. You can also set these up to search for zeroes instead, or both zeroes and ones - but more on that in the paper above.
And it goes without saying that every additional layer is 64 times smaller than the 1st. So for the example above with 1073741824 bits in the first layer, or 16777216 words, you're looking at an additional 262144 words for the 2nd layer, 4096 for the 3rd layer and 64 for the 4th layer. So there's an inverse relationship between the amount of memory you spend and the amount of optimisation gained for each layer, which is strange but makes sense.
Well, I suppose I should note that hive ie. colony but with a buzz, made it through plenary. So it's in C++26, basically. This is good. It's weird how little I feel about it. Not in a bad way, but just in a 'huh' way. Okay so that happened. I guess the fact is that by the end of it, the paper was so much more a team effort. There's still a little bit of work to do. Not on the paper, just the implementation. I'd like to thank everybody I thanked in the paper, but, like, again. It's done.
I needed a bitset for something so I wrote one - well, two actually. And then later, three. The second was more a matter of realising I could improve on the std:: library implementations a bit. So, introducing plf::bitset (the second one), and plf::bitsetb, being the one I developed initially. The latter takes a user-supplied buffer and size as constructor arguments, meaning, you can treat any block of memory as a bitset. Both bitsets take the storage type as a template argument, so in most cases you can use your external buffer without reinterpret_cast'ing the pointer to it (so long as it's a trivial POD type). The template argument also allows you to reduce the storage size of your bitset to the smallest possible type ie. a byte, meaning you won't get as much wasted memory if your bitset size doesn't happen to align exactly with your systems word type (like you would with std::bitset). plf::bitsetc came late in development and is basically a C++20-only custom version of bitsetb which allocates it's own buffer on the heap instead of taking a user-supplied on. How this can be useful vs plf::bitset is explained on the project page.
The bitsets also introduce new features: set_range and reset_range, which set a range of indexes to 1 or 0 respectively, improving upon doing the same thing individually using set(pos)/reset(pos) by around 34652%/67612% (GCC/MSVC, O2 AVX2) on average. There are also optimized functions for finding the index of the first or last 1 or 0 in the bitsets, and a non-allocating swap() function (using the XOR method). Lastly, I provided additional to_string functions to obtain the string in the correct, index-oriented way - not backwards.
plf::bitset hosts it's own stack-allocated buffer, like std::bitset, and is more a drop-in replacement for the latter. More details on all three bitsets can be found on the page. All are under a new license: the Computing For Good license. This is more-or-less an ethically-oriented version of the zLib license, so it's still fairly liberal, moreso than GPL but less-so than zLib. As I explain on the license page, all software licenses are ethical, this one just happens to go outside the typically restraint of only focusing on intellectual property rights.
In an ideal world, licenses such as these would not be necessary. But when major tech corps are polluting, stealing user data and violating copyrights left-and-center, it's pretty obvious that the tech industry is not suitable for establishing moral compasses. Seeing the turn of events in recent years has left me wondering why I got so hung up on the positives of tech back in my 2016 speech. If I'd known that the 3 wealthiest tech people in america would be richer than the poorer 50% of the country combined, and that they did nothing of value with their money, I would've stopped right there. Colony would never have been born. But here we are, and it's up to the smaller people, to say no, where and when applicable.
I realised a while ago that info on how to do benchmarks properly is relatively scarce. Here's some brief tips, geared toward small-scale CPU-based benchmarking (as opposed to heavy-duty apps or graphics-oriented apps like games, where the OS background processes play less of a role in results). Most of them are generic, some are specific to C++ and the various compilers:
rand() % power_of_2 to rand() & (power_of_2 - 1) if this is faster.Thee was a misunderstanding about how typedefs affect constness expression in colony/hive/etc. Basically you'd think that:
typedef group * group_pointer_type;
const group_pointer_type current_group;
Would equate to const group * current_group;, but it doesn't. Basically it's not a macro expansion, it's treated as a type separate to group *. Hence it actually becomes group * const current_group;, effectively; ie. a constant pointer to a non-constant group. Anyway, rather than mixing the east/west constness in the files I decided to just go west const. Not a big deal, but I do get rather tired of finding this sort of funky edge-case in this language. Would that it were simpler.
Revisiting python after, let's say, a 26-year absence, it's fascinating to see it in terms of what I've learned about languages from C++ and about performance in general. The fact that everything is an object yields great results on the user front, incredible usability, but terrible results on the performance front for the obvious reason that processors like single functions run on multiple bits of data at once, in batch, not individual functions running adhoc on individual bits of data. OO leans toward the latter. The other thing I think about extends from what I detest about 'auto' - the fact that you're shifting cognitive load onto the code viewer to infer the object type, all for the benefit of saving a few measly keystrokes, and reducing code readability in the process; python does the same thing, but, for everything.
This has broad implications. While python code looks easy to read (and I approve of whitespace-based formatting), so much is hidden that if one wants to infer performance-related information, you have to basically convert everything in your head to see what is being done implicitly - whereas in C++ it is, by and large, written explicitly. It definitely has it's place, and its a fascinating language as a thought experiment along the lines of 'what if we take object orientation to it's logical conclusion?'. And an excellent replacement for all the unstructured, crappy languages that came before it eg. Perl. But it will never be the language of choice for performance code.
The R26 revision of the std::hive proposal (ie. colony but C++20-only and with some differences) is being polled in LEWG for forwarding onto LWG. This revision is the result of a months gruelling part-time refactoring, basically reducing the non-technical-specification sections down to bare essentials, streamlining delivery, removing repetition and any mistakes found. As a consequence it is some 10kb (4%) lighter than before, despite containing additional data for implementors. This is, I believe, one of the few times a C++ paper has gotten significantly Lighter in a subsequent revision - down to a 'mere' 28351 words. I am more proud of this than I should be. If you had asked me back in 2016 whether I would've been willing to write a thesis-length document in order to promote this thing into the standard library, I would've laughed. But there it is.
The talk basically covers all the stuff I do/have done which isn't colony/hive - including a refresher on plf::list. There's also some rambling about time complexity and it's deep irrelevance to most situations nowadays. I do understand the idea behind it - making sure that you can't have odd situations where, at worst, power of 2 complexity can arise but still - it's by-and-large irrelevant now.
I've been reading this book, which is a surprisingly good read for a programming book - clear, concise, with a sense of humour and mature sense of perspective on life (it is unsurprising how often the latter two contribute to each other). It articulates things I already knew, but also gives helpful advice on situations I am less familiar with. There's one thing it missed however, which is 'don't name stuff the same as other stuff'.
I had a situation in code today where within a given function, two variables, one a const clone of the other for backup purposes, since the original value was going to be overwritten, differentiated only by a single character. Specifically, a '.' for the original member variable, and a '_' for it's clone. This was bad! Later on in the code - in fact, the final line - I'd accidentally run a function on the original which was meant to be run on the clone. This would've had potentially bad consequences in the off-chance that the edge case was reached. Many heads may've been scratched systemically and simultaneously.
I am writing this on an HP laptop keyboard, and they are terrible, so if I've misplaced a character here, blame Hewlett-Packard, but in the above case I had no-one but myself to blame. To fix this, I fixed the line, but that was the superficial part of the fix, really. The real fix was to realise that this sort of similarity-naming, while appropriate, can be confusing, and to stop doing it. Hopefully I haven't repeated this pattern too much. Don't Name Stuff The Same!
A user suggested allowing predicate-based versions of unordered_find_single, unordered_find_multiple and unordered_find_all, to match those found in the standard library - this's been implemented. The original functions work the same, but now you can supply a predicate function instead of a value.
Further developments within reorderase: introspection into the nature of erase_if (which is, really, just a partition with an inverted predicate followed by a range erasure) led me to realise that the algorithm I'd developed for reorderase_scan_if (the order-unstable equivalent of erase_if) could be used for partitioning in general. To be clear, I'm talking for bidirectional iterators and upwards, not forward iterators - the forward iterator algorithm I have is the same as those across the major vendors. Further thoughts:
All std::partition methods for non-forward-iterators are the libstdc++ code, just slightly obsfucated. Mine is slightly different. libc++ takes libstdc++'s code and rearranges the ops (and arguably makes it more elegant) while MS's version takes the libc++ version and makes it less elegant, and kinda funny (for (;;) instead of while(true). Well, I laughed). Since mine derived from working on an unstable erase_if, before I worked out the inverted connection with std::partition, I came at it fresh. The only real difference is that one of the loops is nested, which actually removes one loop in total from the equation.
The performance results are as follows: all over the place. That's not due to lack of benchmarking proficiency, though I did have to do some work there to eliminate cache effects. I believe (but do not know for sure) that it's because branch prediction failure recovery cost (say that nine times fast) and loop efficiency differ significantly from architecture to architecture. In addition, type sizeof plays a huge role in the gains measured. The larger the size of the copy/move, the less relevant the effects of the differing code are, and the largest differences are seen with smallest sizeof's.
Generally-speaking, what I can say is that on computers older than 2014, my algorithm performs better - and the older the processor, the better it performs (for example: 17% faster on average for core2's). However, on newer machines, the algorithm which all the major vendors use performs better - generally (there are some outliers - a 2019 Intel mobile processor works better with my algo, for example). All I can say for certain is that you should check on your own architecture to find out.
Now, destructive_partition. This was a suggestion from someone in SG14, though I'm not sure that it has a major use. Basically it does the same thing as my 'order-unstable erase_if' (reorderase_scan_if) in the sense of moving elements rather than swapping them around, hence you end up with a bunch of moved-from elements at the end of the range. What is this good for? Unsure. But inspired by the idea, I came up with sub-range based versions of unordered std::erase_if/std/::erase, which clears a range within the container of elements matching a given predicate, and moves elements from the back of the container to replace them - again, making it the operation's time complexity linear in the number of elements erased.
As to whether erasing from sub-ranges of containers is a common practice, I cannot say - but the possibility is there, now. The functionality comes in the form of overloads to reorderase_all/reorderase_all_if, with the additional first/last arguments. In addition the following boons have been granted to the regular full-container overloads of reorderase_all/reorderase_all_if - they're faster and supports forward-iterator containers like std::forward_list now.
As things so often happen, I chanced upon a concept in a talk by someone else that changed my conceptual boundary for what indiesort could do - not in a big way, mind you, but in a useful way at least. That talk was Bjarne's from earlier this year, and it detailed a very basic idea for sorting a std::list faster: copy the data out into an array, sort the array, copy it back. "Huh", said I. That makes a lot more sense than what I'm doing, at least when the type sizeof is very small - specifically, smaller than 2 pointers. That means it's smaller than the pointer-index-struct which indiesort was using to sort the actual elements indirectly. But copying the elements out and copying them back is also an indirect form of sorting, isn't it?
On realising this I incorporated it into indiesort, for types smaller than the size of 2 pointers. There was no performance improvement, just a memory usage reduction for the temporary array constructed in order to sort the elements. In addition, I was able to apply the same ability to plf::colony (which uses indiesort internally for it's sort() function). I contemplated adding it to plf::list, which uses the precursor to indiesort (it changes previous/next list node pointer values rather than moving elements around), but this would make plf::list less-compatible with std::list. By doing Bjarne's technique, you end up moving elements around instead of changing next/previous pointer values - meaning that pointers/iterators to existing elements would now point to different elements after a sort is performed.
I did try incorporating the behaviour into plf::list, and there was a performance increase of up to 70% (average increase of 15%) across small scalar types (depending on the type and the number of elements being sorted) with the behaviour present. But, of course, the original behaviour is faster/more-memory-efficient with larger elements, and what good is an algorithm which has one guarantee (element memory locations stay stable after sort()) for one type and not for another? Might ask the community. But I overall prefer the idea of being as-much of a drop-in replacement for std::list as possible (lack of inter-list range-splice notwithstanding). [EDIT/UPDATE: I've decided to keep plf::list's sort technique the same, to maximise std::list compatibility, however if someone wants this performance increase ie. up to 70% faster sorting for small scalar types, they can get it by using plf::indiesort with plf::list.]
colony is updated - specifically, I removed one strictly-unnecessary pointer from the block metadata which made some things easier. It took a looooong time to find a way to get everything as performant as it was with the pointer, but now that it is, I'm pretty happy with it. Performance is slightly better for scalar types, and I should have some new benchmarks up at some point. The downside of this breaking change is that advance/next/prev no longer bound to end/cend/rbegin/crbegin, which means you have to bound manually using a </> comparison with your iterator and setting it to end/cend/rbegin/crbegin if it's gone beyond that. In addition plf::colony_limits has been renamed back to just plf::limits. In future I might end up using the same struct across multiple containers, hence the change. Lastly there was a bug in is_active in that if you supplied an iterator pointing to an element in a block which had been deallocated, but then the allocator had used the same memory location for providing a new block, it could cause some issues. That's fixed.
queue and stack are updated - they have iterators/reverse_iterators now, including all the const varieties. Why iterators? Debugging purposes, mainly. It's something people were asking for as far back as 2016, and it didn't take too much effort.
reorderase has new optimisations for range-erase (reorderase(first, last)) and deques. Basically if the range begins at begin(), reorderase will just erase from the front (basically a pop-front for a deque).
indiesort now chooses the appropriate algorithm based on whether the iterators are contiguous or not, at least under C++20 and above. In addition, for non-random-access iterators/containers, if the type size is small and trivally-copyable, it will switch to simply copying the elements to a flat array and sorting that, then copying the elements back. This idea was inspired by this talk by Bjarne Stroustrop.
The rest are much the same.
See the project page for the details, but basically reorderase takes the common swap-and-pop idiom for random-access-container erasure, optimises it, then extends it to range-erasure and erase_if-style erasure. It performs better on larger types and larger numbers of elements, where the O(n) effects of typical vector/deque/etc erasure have strong consequences. The results, on average across multiple types, numbers of elements from 10 to 920000, are:
As a side-note, thinking about making a paper for this. Though my experience with the C++ standards committee so far has not been exactly rewarding, I believe that more people need to know about and understand these processes.
An additional section in the Low-complexity Jump-counting skipfield paper now details how to create a skipfield which can express jumps of up to std::numeric_limits<uint64_t>::max() using only an 8-bit skipfield. There is a minor cost to performance, and introduction of a branch into the iteration algorithm. See "A method of reducing skipfield memory use" under "Additional areas of application and manipulation".
While I am off twitter generally nowadays, occasionally I dive back in to see what the latest bollocks is, and spotted John Carmack's ridiculous post supporting absolutist free speech. While I support Carmack's views as far as programming goes, I find him naive sociologically - and perhaps his perspective is the result of being a thoroughly empowered individual in his society (which he has absolutely earned through his talent). There seems to be ongoing discussion - primarily in America and primarily on social media - debating the worth of free speech. As a NZ'er I always find this a bit awkward, as Americans are, by and large, unaware of how much of a non-event this is internationally.
That is to say most countries with some small exceptions, do not glamourise freedom nor hold freedom of speech as an ideological goal. NZ for example was predominantly founded on ideals of fairness, not freedom - there have been books written about this and the divergence with American ideals. As far as the results of this go, New Zealand always rates near the top of the charts in terms of international standards of individual freedom. America languishes far behind. Why is this?
Well, it turns out that when you drive toward freedom as your central goal, you play down the aspects of fairness which empower individuals in a broader egalitarian way, and entrench power in the hands of those who already hold it. In other words, a society which values freedom above fairness will always result in more freedom for those with the most power. A well-respected, wealthy, well-known individual can always use their clout, power and money to shut down discourse against their activities, without fair checks and balances in place (see: Twitter).
So I am not a massive advocate of free speech. I see the benefit, but much like an emphasis on freedom in general, it tends to result in more freedom for the powerful and less for the less powerful once taken as an ideology. This is not acceptable. Neither am I an advocate of overly kind speech, which once taken as an ideology, tends to result in untruths being spoken to ameliorate the timid or catatonically-reactive. Which is neither kind nor useful, in terms of longer-term outcomes. People need their boundaries and preconceptions pushed, sometimes. What I am in favour of is fair speech, which is, as an ideology, an attempt however flawed to match appropriate action to the given situation, as it occurs.
An example: someone insults you. Free speech response: you can say whatever you want in return. There are no boundaries, which means you can escalate the situation, if you choose to - it all comes down to the individual - that's your right. Free speech advocates sometimes attempt to legitimize the negative outcomes of free speech by declaring "freedom of speech doesn't mean freedom from consequences". This is such an idiotic argument. Typically the negative effects of free speech are on those being spoken at, not the speaker. The higher the power level of the speaker, the less likely negative effects on them are, which means those in power are typically emboldened to be as obtuse and unfair as possible (see: a certain ex-president).
Kind speech response: you are kind and do not react, but neither do you push back against the aggressor. This tends to evolve into passive-aggressive situations, and typically an outcome of gradually socially 'pushing-out' troublesome individuals. Which may work out sometimes, and sometimes it may not. But often it results in the kind of 'cancel culture' over-reactivity which has become so common and toxic to intelligent discourse over the past 2 decades. The end result of which is the same as the result for free speech, only with the power dynamic inverted - those perceived as 'less powerful' are emboldened to be obtuse and unfair.
Fair speech response: balancing the situation against the needs of the aggressor (they may have a legitimate reason to be angry, regardless of how poorly they're handling it), versus your needs (you have limits too - and you might perform worse if they push further), versus what is best for society (if you don't push back, is this person going to do the same thing to someone or something else? Or would pushing back reinforce their negative habit?), what you might do could be 'aggressive', 'assertive', or it could be 'timid' or neutral. The point is not to reach for an set response, but for an appropriate response. A truly kind response can be a hug (metaphorically), or it can be a slap (again, metaphorically). Some people need boundaries, because they can't create them for themselves, or haven't had healthy boundaries demonstrated to them. We don't know, so we guess, make judgements and do our best to rise to the situation appropriately.
Discourse then becomes not about who has the most or least power in the dynamic, but about what is fair between the given individuals or groups. Reaching for an ideal of kindness or freedom-based individualism is not terribly practical, and in a sense is a partial foregoing of one's social responsibility. Those who don't understand the potential value of harsh responses in a social context, I refer to this talk by Jonathan Haidt. Fair speech contains an implication of fairness in terms of ones balancing of individual responsibility with social responsibility. Everybody has their own concept of what is fair and unfair, so it's certainly a grey area with no consensus there, but it's a better North Star to guide towards than kindness or freedom. IMHO.
Colony now includes static constexpr size_type max_elements_per_allocation(size_type allocation_amount) noexcept, which is basically the sister function to block_allocation_amount. Given a fixed allocation amount, it returns the maximum number of elements which can be allocated in a block from that amount. Since colony allocates elements and skipfields together, this isn't something one can work out merely from the sizeof(element_type). This could be useful with allocators which only supply fixed amounts of memory, but bear in mind that it is constrained by the block_capacity_hard_limits(). Which means an allocator which supplies a very large amount of code per allocation, would still only be able to create a block of 65535 elements max (or 255 for very small types), and max_elements_per_allocation will truncate to this.
Philipp Gehring pointed out to me that currently colony, hive et al won't compile if gcc/clang is used and -fno-exceptions specified. I've fixed this, and as a bonus the fix also works with MSVC, which means that if no exceptions are specified in MSVC/clang/gcc (a) then try/catch blocks won't be generated and (b) throw statements change to std::terminate statements. So you get slightly more useful behaviour under MSVC, and the ability to compile in gcc/clang. This change affects hive, colony, list, queue and stack. In addition a couple of unrelated bugs were quashed for colony.
Twitter was always completely sh*thouse. There is a particular sickness of the modern century which seems to result in adults acting like someone's punched their mum in response to relatively banal first-world problems, and the house in which that disease was spread was primarily social media, but really, mostly Twitter. So no big loss? But yeah, no Elon Musk for me.
I looked up at the night sky a few months ago, from a location I won't name, but which has fairly astronomical views in a literal sense, and in the early hours saw a trail of lights litter across the sky in single file. When I was a teenager I saw a daisy plant in a field which had been affected by spray drift from a hormonal pesticide - actually I felt it before I saw it, a massive knowing of 'wrong' eminating from a particular point in the field, only when I got closer I noticed the plant was twisted and warped, with roughly 50 daisy stems growing together, culminating in an ugly half-circle head of those daisy flowers growing as one horrific abomination. Elon Musk's 49 satellites were like that. A great sense of wrong.
There's something callous, even cruel about the idea of using the night sky, something which belongs to no-one, as a fairly blatant way to advertise your product. There's something ego-maniacal about it. I've come across worse people, but at least in terms of services and programs, I won't be using anything by someone who perverts the night sky like that.
And that was *before* all the subsequent bullcrap. I mean, come on. Using your position of power to call out your preference for governance, and in such a low-brow and hypocritical way. Reinstating a clown-in-chief account which was used to pervert due process. And just generally being a dork. So yeah. I had the option to sign up to starlink at my new location, but it got taken away from me and I was glad it did. Nothing's worth that.
I'll always admire pre-drugs Musk - Tesla has done some great work in the world, even Paypal for all it's early illegality was eventually a force for good, or at least less-evil than the alternatives.
This brings colony up to date with the changes in plf::hive over the past year. Overall summary: fewer bugs, better performance, more functionality. It brings support for rangesv3 under C++20, as well as stateful allocators and a few other things. Sentinel support for insert/assign is gone, as this is apparently done via ranges nowadays, and a few new functions are in there:
bool is_active(const const_iterator it) const
This is similar to get_iterator(pointer), but for iterators. For a given iterator, returns whether or not the location the iterator points to is still valid ie. that it points to an active non-erased element in a memory block which is still allocated and belonging to that colony instance. It does not differentiate between memory blocks which have been re-used, or whether the element is the same as when the value was assigned to the iterator - the only thing it reports, is whether the memory block pointed to by the iterator exists in an active state in this particular colony, and if there is an element being pointed to by the iterator, in that memory block, which is also in an active, non-erased state.
static constexpr size_type block_metadata_memory(const size_type block_capacity)
Given a block element capacity, tells you, for this particular colony type, what the resultant amount of metadata (including skipfield) allocated for that block will be, in bytes.
static constexpr size_type block_allocation_amount(const size_type block_capacity)
Given a block element capacity, tells you, for this particular colony type, what the resultant allocation for that element+skipfield block will be, in bytes. In terms of this version of colony, the block and skipfield are allocated at the same time (other block metadata is allocated separately). So this function is expected to be primarily useful for developers working in environments where an allocator or system will only allocate a specific capacity of memory per call, eg. some embedded platforms.
As a note on the latter function, I've experimented with allocating elements+skipfield+other-metadata in a single block, but it always ended up slower in benchmarks than when the other metadata was allocated separately. I'm unsure why that is, possibly something to do with the block metadata mostly not being touched during iteration, so keeping the elements+skipfield together but the other metadata separate may reduce the memory gap between any two given blocks and subsequently increase iteration speed - but I have no idea really.
Generally-speaking, I would prefer using hive over colony nowadays, if you and all your libraries have C++20 support - mainly because C++20 allows me to overload std::distance/next/prev/advance to support hive iterators, whereas because colony must function with C++98/03/11/14/17, it only supports ADL overloads of calls to those functions ie. without the std:: namespace. Also hive is significantly smaller due to the lack of C++03/etc support code - 168kb vs 196kb for colony, at the present point in time. hive lacks the data() function, which gives you direct non-chaperone'd access to colony's element blocks and skipfield, various other sundry functions like operator ==/!=/<=> for the container, and also the performance/memory_use template parameter, which allows colony to change some behaviours to target performance over memory usage. Hive is essentially a simplified and somewhat limited version of colony.
Speaking of the performance/memory template parameter for colony, the behaviour there has changed somewhat in the new version. It was found during discussions of hive (and subsequent testing on my part) with Tony Van Eerd that hive/colony actually performs better with an unsigned char skipfield and the resultant smaller maximum block capacities (255 elements max) when the sizeof(element_type) is smaller than 10 bytes. This makes sense when you think about it in terms of cache space. When the ratio of cache wasted by the skipfield, proportionate to the element sizeof, is too large, the effect of the larger skipfield type is, essentially, to reduce the cache locality of the element block reads by taking up more space in the cache.
When you reduce the skipfield type to a lower bit-depth, this also reduces the maximum capacities of the element blocks, due to the way the jump-counting skipfield pattern works. But it turns out the reduction in locality based on the lowered maximum block capacity is not as deleterious as the reduction in cache capacity from having a larger skipfield type. This effect goes away as the ratio of skipfield type sizeof to element sizeof decreases. So for a element type with, say, sizeof 20 bytes, a larger 16-bit skipfield type makes for better *overall* cache locality.
Hence the default behaviour now is to have an unsigned char skipfield type when the sizeof(element_type) is below 10 bytes, regardless of what the user supplies in terms of the performance/memory_use template parameter. However even in this case, the parameter will be referenced when a memory block becomes empty of elements and there is a decision of whether or not to reserve the memory block for later use, or deallocate it. If memory_use is specified, the memory block will always be deallocated in this case, unless it is the last block in the iterative sequence and there are no other blocks which have been reserved previously.
The latter is a guard against bad performance in stack-like usage, where a certain number of elements are being inserted/erased from the back of the colony repeatedly, potentially causing ongoing block allocations/deallocations if there are no reserved memory blocks. If instead performance (the default) is specified as the template parameter, blocks will always be reserved if they are the last or second-to-last block in the iterative sequence. This has been found to have the best performance overall in benchmarking, compared to other patterns I have tested (including reserving all blocks).
In addition if memory_use is specified, the skipfield type will always be unsigned char and the default max block capacity limit 255, regardless of the sizeof (element_type), so this much has not changed. Further, in benchmarking the latter, some non-linear performance characteristics were found during erasure when the number of elements was large, and these have subsequently been fixed.
The second thing to come out of the aforementioned testing was the discovery that a larger maximum block capacity, beyond a certain point, did not result in better performance, the reason for which is again, cache locality. When the element type is larger than scalar, beyond a certain point there is no gain from larger block capacities because of the limits of CPU cache capacity and cache-line capacity. In my testing I found that while the sweet spot for maximum block capacities (at least for 48-byte structs and above) was ~16383 or ~32768 elements in terms of performance, in reality the overall performance difference between that and 8192-element maximum capacities was about 1%. Whereas the increase in memory usage going from max 8192 block capacities to max 32768 block capacities was about 6%.
Below 8192 max, the performance ratio dropped more sharply, so I've stuck with 8192 as the default maximum block capacity limit when the skipfield type is 16-bit - this is still able to be overridden by the user via the constructor arguments or reshape, up to the maximum limit of the skipfield type. In regards to this, there are 4 new static constexpr noexcept member functions which can be called by the user prior to instantiating a colony:
These functions allow the user to figure out (a) what the default minimum/maximum limits are going to be for a given colony instantiation, prior to instantiating it, and (b) what potential custom min/max values they can supply to the instantiation.
Final note: why does a larger maximum block capacity limit not necessarily scale with performance? Well, you have to look at usage patterns. Given that element insertion location is essentially random in colony/hive, whether a given element in a sequence is likely to be erased later on is also independent of order (at least in situations where we do not want to, say, just get rid of half the elements regardless of their values or inter-relationships with other data). So we can consider the erasure pattern to be random most of the time, though not all of the time.
In a randomised erasure pattern, statistically, you are going to end up with a lot of empty spaces (gaps) between non-erased elements before a given memory block is completely empty of elements and can be removed from the iterative sequence. These empty spaces decrease cache locality, so it is in our best interest to have as few of them as possible. Given that smaller blocks will become completely empty faster than larger blocks, their statistical probability of being removed from the iterative sequence and increasing the overall locality, is increased. This has to be balanced against the lowered base locality from having a smaller block.
So there is always a sweet spot, but it's not always the maximum potential block capacity - unless the ratio of erasures to iteration is very low. For larger element types, memory fragmentation may play a role when the allocations are too large, as may the role of wasted space when, for example, you only have 10 additional elements but have allocated a 65534-element block to hold them in. This is why user-definable block capacity min/max limits are so important - they allow the user to think about (a) their erasure patterns (b) their erasure/insertion-to-iteration ratios and (c) their element sizeof, and rationalize about what the best min/max capacities might be, before benchmarking.
They also allow users to specify block capacities which are exactly, or multiples of, their cache-line capacities, and (via the block_allocation_amount function) match their block capacities to any fixed allocation amounts supplied by a given platform.
Holy carp this is a long blog post. Okay. Now onto the plf::list/plf::queue/plf::stack/etc changes. For plf::list the same changes regards adding ranges support and removing specific sentinel overloads occur. For all containers there are corrections to the way that allocators and rebinds are handled - specifically, stateful allocators are corrected supported now ie. rebinds are reconstructed whenever operator =, copy/move constructors or swap are called. For plf::list and colony it is no longer possible (above C++03) to incorrectly assign the value of a const_iterator to a non-const iterator, and for all containers the compiler feature detection routines are corrected/reduced in size. For even more info, see the version history on each container's page.
A bunch of thoughts on Carbon, in case anyone's interested.
Mostly I support the notion. Culling the dead weight? Great.
Public-by-default classes? As it should be (think about it - when you're prototyping and doing early experimentation, that is not the time to be figuring out what should be publicly visible - privatising members comes later).
Bitdepth-specific types by-default? Excellent!
A different syntax that is maybe, subjectively-better to some people... ehh.
Some aspects of the latter are in my view wrong. All natural languages start with generics and move to specifics (or with the most important thing in that culture first, then to the least), and so do programming languages. We have a heading with the general topic, then a paragraph with the specifics. We have a function name and the arguments, then we do something with those arguments. We would find it very odd to specify the name and arguments at the end of the function. This is not so much about word order as it is about making communicative sense.
With that in mind, consider the following english sentence:
"There was a being, a human named John, who was holding an apple."
We don't say:
"There was a being, whose name was John, a human, who was holding an apple."
because it moves from more specific (John) to less specific (human). Likewise we don't tend to say:
"An apple was being held by John, who was a human, and a being."
But Carbon variable declarations look like this:
var area: f32 = 1;
Break that down: var is the least specific aspect (because there are many, many vars), the type of var (f32) is the second least specific (because there may be many f32's), the name is more specific (because there is only one of this name) and the value is the most specific (because it is a value ascribed to the specific name).
So it should look like:
var f32 area = 1;
Except that 'var' is completely superfluous, in terms of human parsing at least (most vexing parse ignored for the moment).
In the following sentence:
"There was a being, a human named John, who was holding an apple."
"being" is implied by "human". We know that humans are beings, and therefore in most cases we would say:
"There was a human named John, who was holding an apple."
This seems more natural.
Similarly, I think saying:
f32 area = 1;
is perfectly natural, as 'var' is implied by f32, and a function cannot begin with f32, and functions are prefixed by 'fn' anyway. Thus we come back to C++ syntax. There may be a desire to move away from that, based on simply wanting something different, but I don't see a logical or intuitive case for it. Is the most vexing parse (the supposed logical reason for inclusion of 'var') really that big a problem? I'd never even heard of it before reading about Carbon.
Other thoughts: no easily-available pointer incrementation? Then how do you make an efficient vector iterator? Or a hive iterator, for that matter? (Don't say 'indexes' - every time I've benchmarked indexes vs pointers over the past ten years, pointer incrementation wins - you always have to have an array_start+index op for indexes, which is two memory locations, rather than a ++pointer op, which is one). Likewise, if pointers cannot be nulled, what does that mean? You still need a magic value to assign to pointers which no longer point to something - otherwise there's no way of checking whether a pointer is still valid, by a third party. Either I'm missing something in both of these cases, or there is a lack of clear thinking here.
There's also a few other things I would useful to fix. I don't see simplified support for multiple return values from a function. Something as straightforward as:
fn Sign(i: i32, j: i32) -> i32, i32
, where the return statement also supports comma-separated returns:
return 4, 5;
would be a simpler way forward than the current solution of tuple binding/unbinding.
Anyway. I think Carbon has potential, but as to whether it is going to be better than C++, or merely a substitute for people who like a particular way of doing things, with it's own share of downsides, remains to be seen. Jonathan Blow's 'jai' language started with a very clear vision - be a C-like replacement language specifically for games. I get the feeling that at this point, Carbon doesn't realise how specific it's vision is, and what fields it might be excluding. At the moment it's making containers harder to make, for example, by excluding pointer arithmetic. There's certainly time for people to get on board and move the goalposts, but for me personally I find honesty to be a necessity for any community, and the leads in Carbon have made it clear that they don't believe this is worth putting in their Code of Conduct.
This guide was developed to aid in people's thinking about which container they should be using, as most of the guides I'd seen online were rubbish. Note, this guide does not cover:
These are broad strokes and can be treated as such. Specific situations with specific processors and specific access patterns may yield different results. There may be bugs or missing information. The strong insistence on arrays/vectors where-possible is to do with code simplicity, ease of debugging, and performance via cache locality. I am purposefully avoiding any discussion of the virtues/problems of C-style arrays vs std::array or vector here, for reasons of brevity. The relevance of all assumptions are subject to architecture. The benchmarks this guide is based upon are available here, here. Some of the map/set data is based on google's abseil library documentation.
a = yes, b = no
0. Is the number of elements you're dealing with a fixed amount? 0a. If so, is all you're doing either pointing to and/or iterating over elements? 0aa. If so, use an array (either static or dynamically-allocated). 0ab. If not, can you change your data layout or processing strategy so that pointing to and/or iterating over elements would be all you're doing? 0aba. If so, do that and goto 0aa. 0abb. If not, goto 1. 0b. If not, is all you're doing inserting-to/erasing-from the back of the container and pointing to elements and/or iterating? 0ba. If so, do you know the largest possible maximum capacity you will ever have for this container, and is the lowest possible maximum capacity not too far away from that? 0baa. If so, use vector and reserve() the highest possible maximum capacity. Or use boost::static_vector for small amounts which can be initialized on the stack. 0bab. If not, use a vector and reserve() either the lowest possible, or most common, maximum capacity. Or boost::static_vector. 0bb. If not, can you change your data layout or processing strategy so that back insertion/erasure and pointing to elements and/or iterating would be all you're doing? 0bba. If so, do that and goto 0ba. 0bbb. If not, goto 1. 1. Is the use of the container stack-like, queue-like or ring-like? 1a. If stack-like, use plf::stack, if queue-like, use plf::queue (both are faster and configurable in terms of memory block sizes). If ring-like, use ring_span or ring_span lite. 1b. If not, goto 2. 2. Does each element need to be accessible via an identifier ie. key? ie. is the data associative. 2a. If so, is the number of elements small and the type sizeof not large? 2aa. If so, is the value of an element also the key? 2aaa. If so, just make an array or vector of elements, and sequentially-scan to lookup elements. Benchmark vs absl:: sets below. 2aab. If not, make a vector or array of key/element structs, and sequentially-scan to lookup elements based on the key. Benchmark vs absl:: maps below. 2ab. If not, do the elements need to have an order? 2aba. If so, is the value of the element also the key? 2abaa. If so, can multiple keys have the same value? 2abaaa. If so, use absl::btree_multiset. 2abaab. If not, use absl::btree_set. 2abab. If not, can multiple keys have the same value? 2ababa. If so, use absl::btree_multimap. 2ababb. If not, use absl::btree_map. 2abb. If no order needed, is the value of the element also the key? 2abba. If so, can multiple keys have the same value? 2abbaa. If so, use std::unordered_multiset or absl::btree_multiset. 2abbab. If not, is pointer stability to elements necessary? 2abbaba. If so, use absl::node_hash_set. 2abbabb. If not, use absl::flat_hash_set. 2abbb. If not, can multiple keys have the same value? 2abbba. If so, use std::unordered_multimap or absl::btree_multimap. 2abbbb. If not, is on-the-fly insertion and erasure common in your use case, as opposed to mostly lookups? 2abbbba. If so, use robin-map. 2abbbbb. If not, is pointer stability to elements necessary? 2abbbbba. If so, use absl::flat_hash_map<Key, std::unique_ptr<Value>>. Use absl::node_hash_map if pointer stability to keys is also necessary. 2abbbbbb. If not, use absl::flat_hash_map. 2b. If not, goto 3. Note: if iteration over the associative container is frequent rather than rare, try the std:: equivalents to the absl:: containers or tsl::sparse_map. Also take a look at this page of benchmark conclusions for more definitive comparisons across more use-cases and hash map implementations. 3. Are stable pointers/iterators/references to elements which remain valid after non-back insertion/erasure required, and/or is there a need to sort non-movable/copyable elements? 3a. If so, is the order of elements important and/or is there a need to sort non-movable/copyable elements? 3aa. If so, will this container often be accessed and modified by multiple threads simultaneously? 3aaa. If so, use forward_list (for its lowered side-effects when erasing and inserting). 3aab. If not, do you require range-based splicing between two or more containers (as opposed to splicing of entire containers, or splicing elements to different locations within the same container)? 3aaba. If so, use std::list. 3aabb. If not, use plf::list. 3ab. If not, use hive. 3b. If not, goto 4. 4. Is the order of elements important? 4a. If so, are you almost entirely inserting/erasing to/from the back of the container? 4aa. If so, use vector, with reserve() if the maximum capacity is known in advance. 4ab. If not, are you mostly inserting/erasing to/from the front of the container? 4aba. If so, use deque. 4abb. If not, is insertion/erasure to/from the middle of the container frequent when compared to iteration or back erasure/insertion? 4abba. If so, is it mostly erasures rather than insertions, and can the processing of multiple erasures be delayed until a later point in processing, eg. the end of a frame in a video game? 4abbaa. If so, try the vector erase_if pairing approach listed at the bottom of this guide, and benchmark against plf::list to see which one performs best. Use deque with the erase_if pairing if the number of elements is very large. 4abbab. If not, goto 3aa. 4abbb. If not, are elements large or is there a very large number of elements? 4abbba. If so, benchmark vector against plf::list, or if there is a very large number of elements benchmark deque against plf::list. 4abbbb. If not, do you often need to insert/erase to/from the front of the container? 4abbbba. If so, use deque. 4abbbbb. If not, use vector. 4b. If not, goto 5. 5. Is non-back erasure frequent compared to iteration? 5a. If so, is the non-back erasure always at the front of the container? 5aa. If so, use deque. 5ab. If not, is the type large, non-trivially copyable/movable or non-copyable/movable? 5aba. If so, use hive. 5abb. If not, is the number of elements very large? 5abba. If so, use a deque with a swap-and-pop approach (to save memory vs vector - assumes standard deque implementation of fixed block sizes) ie. when erasing, swap the element you wish to erase with the back element, then pop_back(). Benchmark vs hive. 5abbb. If not, use a vector with a swap-and-pop approach and benchmark vs hive. 5b. If not, goto 6. 6. Can non-back erasures be delayed until a later point in processing eg. the end of a video game frame? 6a. If so, is the type large or is the number of elements large? 6aa. If so, use hive. 6ab. If not, is consistent latency more important than lower average latency? 6aba. If so, use hive. 6abb. If not, try the erase_if pairing approach listed below with vector, or with deque if the number of elements is large. Benchmark this approach against hive to see which performs best. 6b. If not, use hive. Vector erase_if pairing approach: Try pairing the type with a boolean, in a vector, then marking this boolean for erasure during processing, and then use erase_if with the boolean to remove multiple elements at once at the designated later point in processing. Alternatively if there is a condition in the element itself which identifies it as needing to be erased, try using this directly with erase_if and skip the boolean pairing. If the maximum is known in advance, use vector with reserve().
I tend to think of the spaceship operator as a classical example of over-thinking - like the XKCD comic where there's too many standards, so they add another standard. Unfortunately the documentation surrounding it is close to opaque in terms of referencing standardese that no clear-minded student would even consider trying to understand. I've read it and I still don't understand it.
Having said that, it is now implemented in all containers. I had also thought about adding a function to colony/hive which gives the user a way to assess the memory usage of the metadata (skipfield + other stuff) for a given block capacity, then I realised one can calculate this by creating a colony with the given block capacity as a minimum capacity limit, then calculating memory() - (sizeof(colony<t>) + (capacity() * sizeof(t))). But as a convenience function I've put static constexpr size_type block_metadata_memory(const size_type block_size) in colony, for the moment.
Where do we go wrong with our thinking about categories? I like to think of the classic example of the lump of wood and the chair. Take a lump of wood and by degrees gradually transform it into a chair. At what point does it become a chair? Aristotelian logic does not have an answer. Fuzzy logic, sort of, does. By degrees, it is a chair - that is to say at a certain point it maps 40% to what most of us would consider a chair, based on what our brains input of what a 'chair' is (based on examples we have been given) and our own personal aggregate experience of chairs. Then later, 55% a chair, and so on and suchforth. The question is wrong: it's not, "when is it a chair?" or worse, "when do we all agree it's a chair?" - it's "to what extent does it map to our concept of a chair?". The reality is, there's just stuff, and stuff happening. There's a particular configuration of atoms, and we map that to the concept 'chair' based on what is valuable to us. If a chair didn't have any utility to us (be that function or beauty (beauty being an attraction to what is functional to us in some manner, biologically-speakin')) we wouldn't bother to name it, most likely.
A chair doesn't exist, our concept of chair utility exists, and we map that onto our environment. The question of 'what is art?' follows the same guidelines, as art has multiple utilities that are not consistent from 'artwork' to 'artwork'.
So now we get onto the programming side of things. Classical polymorphism is an extension of this original misunderstanding - class chair, subclass throne, subclass beanbag etc. At what point is it not 'of class chair'? That's the wrong question. Map to the utility. And since things rarely have less than two modes of utility, this is where data-oriented design steps in. I'm thinking specifically of ECS design in this case. What properties does this object have? Yes it's a chair, but is it breakable? Is it flammable? What are the modes of utility we are mapping for in any given project? After that point, apply whatever label you want. Whereas polymorphism over-reaches and falsely assigns the importance of the label itself as being comparable to the utility of the object.
It turns out this is a far more useful way of thinking about things, albiet one that requires more care and attention to specifics. One that matches our biology, not the aristotelian abstraction that's been ladled on top of that for millenia. For starters it's much easier to extract the utility, and secondly it's a more efficient way of -thinking- about the objects. We are just a collection of atoms. Programs are just a collection of bytes. Map to that.
To be clear, I'm still running with hive for the standards committee proposal, however I realised that the proposal is significantly divergent from the colony implementation, so I've setup hive as it's own container, separate from colony. The differences are as follows:
The result is a container which (currently as of time of writing) only runs under GCC10, until MSVC and clang get their act together regards C++20 support, and which is 24kb lighter. Hive won't be listed on the website here as it doesn't fit the PLF scope ("portable library framework", so C++98/03/11/14/17/20 and compatible with lots of compilers), however it'll be linked to on the colony page.
The other advantage of keeping colony separate from hive is that colony is insulated from any future changes necessitated to hive, meaning it becomes a more stable platform. Obviously any good ideas can be ported in between hive and colony.
There was a casual minor mistake in the Random access of elements in data containers which use multiple memory blocks of increasing capacity paper (also know as 'POT blocks bit tricks', now updated). The 5th line of the equation should've read "k := (b != 0) << (b + n)" but instead read "k := (j != 0) << (b + n)" which neither matched the earlier description of the equation in the paper, nor my corresponding C++ code. This resulted in the technique not working in the first block, which it does now if you follow it through.
While it might've been noticed by some of the more observant, colony is now optionally typedef'd as hive, as this is the name the committee feels more comfortable with going forward. In terms of my implementation the default name will always be colony, as that's the name I am most comfortable with. There is a paper which explains the name change here. The typedef is only available under C++11 and above due to the limitations of template typedefs in C++98/03. plf::colony_priority and plf::colony_limits are also typedef'd as plf::hive_priority and plf::hive_limits. I'm not... 100% happy about the change, but c'est la vie.
In order to reduce the memory footprint of plf::queue compared to std::queue, there are now two modes that can be selected as a template parameter. 'Priority' is now the second template parameter, before Allocator, as I figure people will likely use Priority more. But at any rate, the new default mode, priority == plf::memory, tends to break the block sizes down into subsets of size(), whereas the original mode, priority == plf::speed, tends to allocate blocks of capacity == size(). The performance loss is relatively low for plf::memory and is still faster than std::deque in a queue context, but the memory savings are massive. More information can be found in the updated 'real-world' benchmarks.
Let's explore the idea of basing design of a product on benchmarks. There are a number of flaws with this: for starters, you can't do an initial design based on benchmarks, you have to build something to benchmark first. So you need an initial concept based on logic and reasoning about your hardware, before you can begin benchmarking. But, in order to get that initial logic, you have to know basic performance characteristics and how they are achieved on a code level - and the only way to know that is via benchmarks either yourself or someone else has done on other products in the past (or having an in-depth mechanical knowledge of how things are working on the hardware level). Otherwise you're just theorising about the hardware, which has limitations.
The second flaw is that, of course, benchmark results will change based on your platform (and compiler) - a platform with a cacheline width of, say, 4k, will benchmark differently from one with a width of 64k. But unless you actually benchmark your code on at least One platform, you don't really know what you're dealing with. And most platforms are reasonably similar nowadays in the sense of all having heavily-pipelined, branch-predicted, cache-locality-driven performance.
So I'm exploring the idea here of benchmark-based design, which is, beyond the initial drawing board part of design, at a certain point you flip over into basing design changes based on what your benchmarks tell you. Nothing revelatory here, something which most companies do, if they're any good. But you want to put the horse before the cart - this involves trying things you think might not work, as well as things you think might. You might be surprised how often your assumptions are challenged. The important part of this is discovering things that work better, then working backwards to figure out how and why they do that.
I've found this kind of workflow doesn't sync well with the use of git/subversion/mercurial/etc, as often I'm benchmarking up to 5 different alternative approaches at once across multiple types of benchmark (if not several different desktops) to see which ones work best. That's how I get performance. But tracking that number of alternative branches with a git-like pipeline just overcomplicates things to no end. So my use of github etc is purely functional - it provides a common and accepted output for those wanting the stable builds.
To expand upon this, plf::queue's original benchmarks were based on the same kind of raw performance benchmarks I used with plf::stack - however this was, somewhat, inappropriate, given that the way a queue is used is very different from the way most containers are used. So I put together a benchmark based on more 'real world' queue usage - that is to say, having an equal number of pushes and pops most of the time, then increasing or decreasing the overall number of elements at other points in time - and tracking the overall performance over time. The intro stats on the queue homepage have been updated to reflect this.
This obviously yielded somewhat different results to the 'raw' stack-like benchmarks, and while the results were still good, I felt I could do better. After reasoning about what the blocks in the stack were doing for a while, I tried a number of different approaches, including some I thought logically couldn't improve performance, and found that some of the more illogical approaches worked better. But I also tracked memory usage and found that the more 'illogical' techniques were using lower amounts of memory, and were also able to re-use the blocks more often, which explained things. Using this new knowledge I was able to construct new versions which not only used less memory (more-or-less on a par with std::queue) but performed better.
Benchmarking in this way is tedious - any good benchmark has to be tested against multiple element types and double-checked on alternative sets of hardware. but when I see people out there making performance assumptions about code, when they haven't actually benchmarked their assumptions, I know this is the right way. You can't guarantee performance if you don't perform.
The most recent v2.0 plf::list update is more of a maintenance release than anything revelatory - though it does fix a significant bug in C++20 sentinel range insert (insert(position, iterator_type1, iterator_type2)), adds sentinel support to assign, overhauls range/initializer_list insert/assign with the same optimisations present in fill-insert, and adds support for move_iterator's to range insert/assign.
The other thing it does is add user-defined sort technique use to sort() - via the PLF_SORT_FUNCTION macro. Ala colony, the user must define that macro to be the name of the sort function they want sort() to use internally, and that function must take the exact same parameters as std::sort(). This means you can use std::stable_sort, and others like gfx::timsort. In addition that macro must be defined before plf_list.h is #included. If it is not defined, std::sort will be the function used. It still uses the same pointer-sort-hack to enable sorting, but for example, stable sorting may be more useful in some circumstances.
Taron M raised the idea of implementing a faster queue, given that std::queue can only run on deque at best, and std::deque's implementation in both libstdc++ and MSVC mean that it effectively becomes a linked list for element types above a certain size. Which is a bit bogus. The result is plf::queue, which is a *lot* faster than std::queue in real-world benchmarking, as in:
* Averaged across total numbers of elements ranging between 10 and 1000000, with the number of samples being 126 and the number of elements increasing by 1.1x each sample. Benchmark in question is a pump test, involving pushing and popping consecutively while adjusting the overall number of elements over time. Full benchmarks are here.
Structurally it's very similar to plf::stack, which made it relatively easy to develop quickly - multiple memory blocks, 2x growth factor, etcetera. We initially spitballed a few interesting ideas to save space in the event of a ring-like scenario, such as re-using space at the start of the first memory block rather than creating a new one; but ultimately the overhead from doing these techniques would've both complicated and killed performance. Also, it has shrink_to_fit(), reserve(), trim() and a few other things, much like plf::stack.
I was investigating a particular trick I'd used for 4-way decision processes in colony, as part of my speech writing process for my talk at CPPnow! 2021. Initially I held my current line, which was that using a switch for this process resulted in better/faster compiler output, both in debug and release builds. This used to be true at one point, however I realised that was a long time ago, and the container had changed since then, and the compilers had changed substantially since then, sooo. Was this still true?
The trick itself involves situations where you have a 3 or 4-way if/then/else block based on the outcome of two boolean decisions, A and B. You bitshift one of the booleans up by one, combine the numbers using logical OR, and put your 3/4 outcomes in 3 switch branches. Initially I did some assembly output analysis based on this simple set of code:
int main()
{
int x = rand() % 5, y = rand() % 2, z = rand() % 3, c = rand() % 4, d = rand() % 5;
const bool a =(rand() % 20) > 5;
const bool b =(rand() & 1) == 1;
if (a && b) d = y * c;
else if (a && !b) c = 2 * d;
else if (!a && b) y = c / z;
else z = c / d * 5;
return x * c * d * y * z;
}vs this code:
int main()
{
int x = rand() % 5, y = rand() % 2, z = rand() % 3, c = rand() % 4, d = rand() % 5;
const bool a =(rand() % 20) > 5;
const bool b =(rand() & 1) == 1;
switch ((a << 1) | b)
{
case 0: z = c / d * 5; break;
case 1: y = c / z; break;
case 2: c = 2 * d; break;
default: d = y * c;
}
return x * c * d * y * z;
}And, indeed the switch version produced about half the number of branching instructions, at both O0 and O2. However this was inconsistent between compilers (MSVC was the worst, producing 10 (!) branching instructions for the O0 build. How? Also - WWWWhyyyyy???). Here's some graphs from the (now removed) slides:
As you can see there's a significant difference there. All compilers are their most recent non-beta versions at the time of writing. But assembly analysis is not benchmarking. So I proceeded to change all the four-way branches in colony itself to a variety of different configurations - some using switch as above, some using if, some using if but with logical AND instead of && as above. I tested across a wide variety of benchmarks in the benchmark suite, and found that I was wrong. The switch variant was no longer in the fore as far as performance was concerned, though it was for earlier versions of GCC (circa GCC5). In the end I went with a logical AND variant, as it seems to have better performance across the largest number of benchmarks.
So now you know - doing a C++ talk can sometimes result in better code.
Also, I now have a new paper, as promised - on modulated jump-counting patterns. These allow a user, for example, to have 2 or more different types of objects in the array/storage area which the skipfield corresponds to, and conditionally skip-or-process either type of object during iteration. For example, in an array containing red objects and green objects, this allows the dev to iterate over only the red objects, or only the green objects, or both, with O(1) ++ iteration time. It is an extension and modification of jump-counting skipfields and can be used with either the high or low-complexity jump-counting skipfields. I am unsure of what this might be entirely useful for at this point - possibly some kind of very specific multiset.
I have another paper in the pipeline, this time describing a new application of modified jump-counting skipfields, but this paper is something different:
Random access of elements in data containers using multiple memory blocks of increasing capacity
It describes a method which allows the use of increasingly-large memory block capacities, in random-access multiple-memory-block containers such as deques, while retaining O(1) access to any element based upon it's index. It's not useful for colony, but it may be useful for other things. I have a custom container based on this principle, but it's not ready for primetime yet - it hasn't been optimized. Ideally I'd get that out the door before releasing this, but we none of us know when we're going to die, so might as well do it now.
The method requires a little modification for use in a deque - specifically, you would have to expand the capacities in both directions, when inserting to the front or back of the container. But is doable. I came up with the concept while working on plf::list, but have subsequently seen others mention the same concept online in other places. But no-one's actually articulated the specifics of how to do it, which is what this paper intends.
Hopefully is of use.
If I could summarise data-oriented design in a heartbeat, it would be that:
traditional comp sci refocuses on micro perf too much, whereas most of the actual performance changes happen at the macro structure level, and what constitutes optimal macro level structure largely changes from platform to platform so it's better to provide developers with the right tools to fundamentally manage their own core structures and code flow with ease and simplicity, to match those platforms, rather than supplying those structures yourself and pretending the micro-optimisations you're doing on those structures are going to have a major impact on performance.
Making things more complicated in order to obtain minor performance optimisations (like the majority of std:: library additions) obscures and complicates attempts to make the real macro changes. Memorising the amount of increasingly verbose nuance necessary to get the nth-level performance out of the standard library does not contribute necessarily to better code, cleaner code, or more importantly, better-performing code.
I note this with full awareness of the part I have to play in bringing colony to the standard, or attempting to do so. It is better to have this thing than not to have it; that's the core thing. It is an optional macro level structure that can have a fundamental impact on performance if used instead of, say, std::list or vector in particular scenarios. But the amount of bullcrap I've had to go through in terms of understanding all the micro-opt/nuance stuff in C++ like allocators vs allocator_traits, alignment, assign, emplace vs move vs insert etc, has been a major impediment to progress.
Ultimately fate will decide whether this was worth it. I'm erring on the side of 'maybe'. Object orientation isn't going away anytime soon, so it's best that programmers have adequate tools to reach performance milestones without reinventing wheels.
In summary, Keep It Simple + think macro-performance, largely.
[Update - in '22 I realised that the version I had of colony which was purported to be constexpr was in fact not, because constexpr cannot utilize reinterpret_cast - at the time of writing this I did not realise this, and also the bugs and performance issues I noted were compiler bugs which finally disappeared in either late '22 or early '23].
Constexpr-everything hasn't been critically-assessed. There is the potential for cache issues when constexpr functions return large amounts of data, or when functions returning small amounts of data are called many times, for example, and the issue of where that data is stored (stack or heap) and how long it is available for (program lifetime?). There is an awful mess of issues for any respectable compiler to sort through, and I don't envy those developers.
What is clear is that it is not a necessary win. My own testing has shown constexpr-everything versions of colony to underperform the original by 2% when using GCC10 in regular code and while I haven't looked into why this is to any great extent, my guesses are along the lines of the following:
For an example of the latter, think about size() in std::vector. This can be calculated in most implementations by (vector.end_iterator - vector.memory_block), both of which will most likely be in cache at the time of calling size(). That's if size isn't already a member variable. Calculating a minus operation from stuff that's already in cache is about 100x faster than making a call out to main memory for a compile-time-stored value of this function, if that is necessary.
In addition constexpr function calls
At any rate, I have a constexpr-everything ver of colony, if people want to try such things out. Just email me.
This was originally intended to be a chapter in what was to be a Data Driven Design fieldguide book based on various author's experiences, spear-headed by Mike Acton, way back in 2019. Unfortunately that book never came to fruition, so rather than leave this writing to dissolve into digital dust, I've guest-published it on Arne Mertz's blog - which has been sadly dormant of recent. Maybe someone else should volunteer to write something as well?
The new version of colony manages to bypass the bad GCC9/10 optimisation bug which dropped performance in certain tests by up to 6-10%. I'm not sure what caused the bug exactly, but hopefully they figure it out. In this case, it seems to've been bypassed by refactoring out some common code into functions, suggesting potentially a GCC bug in large functions. Also, the other benefits are there's less code now, and certain benchmarks perform better even with GCC8. So all good.
The path to finding this 'solution' was fairly circuitous, involving me realising what a load of BS RAII is sometimes. It's nice when it works, but when you figure out that objects allocating their own sub-objects (as opposed to simply incorporating subobjects as flat data or arrays within the parent object) can lead to a much larger number of allocations/deallocations/try-and-catch blocks than is really necessary, you have to wonder just how much of IT infrastructure is slowed down by A instantiating child object B which in turn instantiates C etc. Object orientation is nice, to a point; it helps you think about code. But the buck should stop there. When you are able to see what your design is doing performance-wise with your data as you're supplying it, that can become your orientation from that point onwards.
plf::rand is an adaptation of Melissa O'Neill's lightning-fast PCG random number generator with a fallback to xorshift for C++98/03. Read the page for details on the whys and wherefores of why C's rand() isn't good enough for most benchmarking. In addition, thanks to Tomas Maly, Colony now has much better support for over-aligned types. In the past, I initially allocated the memory blocks for the elements and skipfield of each group structure separately (a group is an element memory block + metadata struct). However, thankfully someone pointed out to me that this was needless and only one allocation per group was necessary. The downside came in the form of allocators not being fully aware of the alignment requirements of the allocation (since I was allocating in unsigned chars of enough size to cover both the elements and skipfield).
This meant that although the type's spacing between elements was maintained by the type itself, allocations were not aligning to a memory locaiton divisible by the alignment itself. This meant two things: SIMD wasn't actually possible, and performance wasn't as good as it could be. By aligning correctly via Tomas's suggested code and my subsequent adaptations, 2% performance increase has been realised in high-modification (large amounts of insert and erase) benchmarking in non-SIMD code, and SIMD code is now possible, as long as one bears in mind the limitations of using SIMD with a colony container.
Since we lose speed if we allocate the skipfield and element memory blocks separately, Tomas's idea was to allign a block in multiples of the element's alignment - this by necessity increases the memory usage slightly, as the chances of the skipfield + elements total size is unlikely to be an exact multiple of the type alignment. However the more elements you have in the colony, the more insignificant this memory usage difference becomes, simply because the total element capacity of each group becomes larger. In the current code, without doing any reserve()'ing or specifying minimum/maximum block capacities, at 100 small-struct (48-byte type) elements inserted individually) there is approximately 1 byte wasted per-element compared to the previous non-aligned code. However at 1000 elements this becomes around 0.1 byte per element, and at 100000 elements it's around 0.001 bytes per element, etc. So, the tradeoff it worth it.
So as it turns out, the phrase "it takes a village to raise a child" is also largely true of good code.
Well that was fast. Anyway, non-member std::erase and std::erase_if overloads for colony are now implemented - for those who're unfamiliar, these're effectively the equivalent of remove and remove_if in std::list - erase if == value, or erase if predicate condition is true, respectively. They are C++20 requirements. They've also been added for plf::list, and various redundant assertion removals and macro renamings have been implemented for all three of colony, list and plf::stack. There's also been a correction to the noexcept guarantee of splice (more lenient), and range-erase now returns an iterator.
Specifying a return iterator for range-erase in colony seems almost pointless, given that there's no reallocation, so the return iterator will almost always be the last iterator of the const_iterator first, const_iterator last pair. However if last was end(), the new value of end() (if it has changed) will be returned. end() can change if the memory block it was associated with becomes empty of elements and is therefore removed from the iterative sequence.
In the last case either the user submitted end() as last, or they incremented an iterator that happened to point to the final element in the colony and submitted that as last. The latter is the only valid reason to return an iterator from the function, as it may occur as part of a loop which is erasing elements and ends when end() is reached. If end() is changed by the erasure of an entire memory block, but the iterator being used in the loop does not accurately reflect end()'s new value after the erasure, that iterator could effectively iterate past end() and the loop would never finish.
Colony v6.00 is designed to be more in line with the current proposed draft for the standard library. It also contains numerous improvements such as:
operator = - much faster.For reference, one should not expect perfect performance results under GCC9/10 presently - there's a performance bug which's been discovered here which gets in the way, at least on a small subset of tests. Hopefully it will be fixed. Thankfully the bug does not exist in GCC8 nor any other compiler and overall, performance is better.
For anyone who's been following colony development you already know that some of the constructors have been modified to take a minimal struct called plf::limits - this contains a min and max size_t member, and a constructor. It allows block capacity limits to be supplied by the user to constructors without creating overload conflicts with the fill constructor. It is also used now by the reshape() and block_limits() functions - which are the new names for the set_block_capacity_limits() and get_block_capacity_limits() functions. In consultation with SG14, the feeling was that 'reshape' better described the function's behaviour, as it will adjust existing memory block sizes where necessary and reallocate elements.
In addition, there were several helper functions which were easily replicated by combinations of other functions - these have been removed:
The main point of doing this was to present a minimal interface for the user, and only provide supplementary functions where critical - for example, get_iterator_from_pointer() still exists because it is not replicable with other functions.
I can expect this implementation to change subtley as the standardisation process continues - if it continues. For anyone wanting a more concrete solution which will not change (but without the above benefits as have been explained), the final version of colony v5 + it's documentation will be maintained here. Any serious bugs that are discovered, will be fixed in this version as well going forward.
Stay safe, keep healthy, and keep coding-
Matt out.
plf::indiesort grew out of the plf::list project, which used a similar technique for it's internal sort function. Unlike indiesort, plf::list's sort is able to just change the previous/next pointers rather than reallocating elements, so it's a lot faster. But indiesort has it's place outside of plf::list. For one, it's much faster for use with std::list than std::list's own internal sort function, asides from when dealing with large types. And for other containers, it does a great job of cutting down sort time (compared to std::sort) when dealing with large or non-trivally-copyable/movable types - up to 130% faster in a vector or array.
How does it achieve this? The basic approach is, create an array with pointers to each element, then sort the pointers instead of the elements, via the value of the elements they point to. The difficult part was then finding a way of redistributing the elements again without just brute force copying them all into a temporary buffer then back to the range/container (which is what I initially did with colony's sort()). Eventually I worked out the most efficient solution, which only requires one element to be copied into a memory buffer as opposed to all of them.
Hence, most elements only get copied once using this technique, some twice, and some not at all (if they haven't moved during sorting). So for any situation where copying an element is expensive, it shines. And of course, the sort techniques which rely on random-access are typically much, much faster than those which don't (another reason why std::list::sort() is slow).
There's a point in time in every man's life where he reflects upon the mistakes he made. Today is not that day. Today is the day I tell you about how I'm fudging my mistake. Without further ado, here is the problem:
The original skipfield pattern used by colony was the 'advanced jump-counting skipfield pattern'. How did it get that name? Well, for starters, a jump-counting skipfield pattern does exactly that - it counts the jumps between one non-skipped item and the next, in an efficient manner. The difference between what I previously called the 'advanced jump-counting skipfield' and the 'simple jump-counting skipfield' was that one was, to my way of thinking at the time, simpler. The 'advanced' pattern did some more complicated stuff. It was also (to my way of thinking at the time, again) more useful essentially - more versatile.
However several years on I started to think about using the 'simple' version in more advanced scenarios - thinking about this only became possible because of some of the different ways I was organising colony on a structural level - but I started to notice that, actually, when viewed in a slightly different manner, it wasn't so much 'simpler' as 'different'. Doing the same things that I did with the 'advanced' version was possible, but required additional data.
To be specific I'm talking about changing a skipped node to an unskipped node. Originally I thought this could not be done with the simple version with any efficiency - while the advanced version stored information in it's nodes about their distance from the beginning of a run of skipped nodes (a 'skipblock'), the simple version didn't. Then I realised it could be done at least for the start and end nodes of skipblock, which do store information. Then I realised (much later) that you could, if you had prior knowledge of the start and end locations of a given skipblock, do anything you wanted to any of the nodes within that skipblock.
As my understand of this pattern grew, and I replaced the skipfield in colony with the 'simple' version, I faced a problem. For starters, it was no longer simpler than the 'advanced' version - it was merely different. But I'd already named, and published, a paper on the advanced version which explicitly stated aspects of the simple version, which were no longer true from my understanding. For this reason, because I needed a new name for this more complex version of the 'simple' pattern, I just called it the Bentley pattern as a working title.
Now, if you know me, or you've been to New Zealand you're realise that this kind of self-aggrandisement (naming an algorithm after oneself) doesn't necessarily sit well with me, or my culture - even though, in computer circles that's what we do all the time - that's where the term 'boolean' comes from (George Boole). But I couldn't think of anything else. However now I feel like I've come up with a solution, although it invalidates the original paper, given that I'm changing both the names for the advanced jump-counting skipfield and the 'simple' jump-counting skipfield.
The fudge is changing 'advanced' to 'high complexity' and 'simple' to 'low complexity', although in this case complexity explicitly refers to time-complexity, not overall complexity of the algorithms. Specifically the low-complexity jump-counting pattern allows for mostly O(1) completion of all operations, but requires additional operational data, which the high-complexity algorithm does not. Many of the procedures of the high-complexity jump-counting skipfield have undefined time complexity, as the amount of work done is determined by the length of any skipblocks involved.
In actual operational practice the performance difference between using the low-complexity and high-complexity algorithms in colony was good but not maximal, as time complexity is not a very good predictor of performance, but any performance increase is worth having. At any rate, I hope that clears things up. For future purposes the current algorithm driving the skipfields in colony is the low-complexity jump-counting pattern, and the previous one was the high-complexity jump-counting pattern. The papers written have been updated to reflect this, and hopefully someday I will find a publisher for the second. They are both available on the main page.
On the plus side I've now been able to re-integrate some of the data I had to cut out of the high-complexity jump-counting paper, in order to make it fit within the original journal's page limits. So now there's info on intersection, parallel processing... etcetera etcetera. Don't get me wrong, they were great - they just had strict limits on how much they could publish. With other journals I've dealt with, the general academic 'stance' is chronically bad, prone to valuing style over substance and valuing the worst criteria as the highest criteria. A lot of grandstanding and adolescent behaviour with a desire to look 'authoritative'. And from what I hear, a lot of academia is prone to this.
Once again Arne has allowed me to spool off my brain noise into bits and bytes, representing characters and other assorted connotations of meaning. Much thanks to him and the post is here, this time the topic is Time complexity and why it's relevance is entirely dependant on hardware, essentially.
I made a modification to plf::colony which enables it to be used with SIMD gather techniques, using the skipfields as masks for processing. I'd like some feedback on how useful this is, and whether it's worth keeping or throwing away. Feel free to email me (see main page).
The way it works in colony is that the skipfield is 0 when an item is unskipped, non-zero when it is skipped. Providing a developer direct access to the skipfield allows them to use SIMD to create a gather mask by transforming the skipfield in parallel to whatever the particular architecture requires eg. for AVX2 and above, this's a vector of integers where each element whose highest bit is one, will be read into SIMD registers.
The new function ( with the underwhelming name of get_raw_memory_block_pointers ), returns a pointer to a dynamically-allocated struct of the following type:
struct raw_memory_block_pointers : private uchar_allocator_type
{
// array of pointers to element memory blocks:
aligned_pointer_type *element_memory_block_pointers;
// array of pointers to skipfield memory blocks:
skipfield_pointer_type *skipfield_memory_block_pointers;
// array of the number of elements in each memory block:
skipfield_type *block_sizes;
// size of each array:
size_type number_of_blocks;
};
There is a destructor so all the sub-struct deallocations are taken care of upon 'delete' of the returned struct.
By using these data sets a programmer can create an appropriate mask for each memory block by processing the skipfield into a separate array/vector, then using that mask perform a Gather operation on the element memory blocks to fetch active elements into SIMD registers. And if desired, and if the processor supports it, a subsequent Scatter back into the colony element memory blocks.
I am wondering how useful this is in comparison to manually creating a mask by iterating over the colony conventionally. The latter approach also ignores memory block boundaries, so might be more useful in that respect, even if you can't use SIMD to create the mask in that case.
There's a demo of how to use the new function in the test suite, which I've just updated in the repo. Let me know how you get on.
This is a tool I've been working on for a while, and deem ready for public service. It automates a lot of changes I make to typical Win10 installations, as well as automating the running of a load of tools such as ShutUp10 and Win10 Debloater. Hope you find it useful.
I never really 'got' constexpr, being a construct that largely does what an optimizing compiler does anyway, but then I read some article by some guy, and it made a bit more sense. Still, I've never found a use for it, much less one that resulted in a performance difference. Then I ran across one scenario where a user had a moveable-but-non-copyable type, and that caused issues with some of the functions which consolidated a colony. Reason was that they were using a function which copy-constructed the existing colony into a new colony, then moved the new colony to the old. This is a shrink-to-fit as far as a colony is concerned.
The copy-construction was obviously a problem for a non-copyable type, so I told the function to move the elements instead if they were movable. However, the branch where elements were copy-constructed was still compiled, resulting in type violation errors, despite the decision being for-all-intents-and-purposes compile-time. This is where constexpr came in handy. With "if constexpr" you can guarantee that the path not taken will not actually be compiled, and by using type traits in conjunction with it you can avoid type errors for branches with operations which would be illegal on that type.
That's, of course, if your compiler supports "if constexpr" properly. Up until some time last year, MSVC had a ton of bugs around constexpr, and all compilers currently seem to require a flag specifying that C++17 is required before they'll enable "if constexpr". With any luck, before the year is out, that might change (being 2 years on since 2017). Regardless, all three constainers - plf::stack, plf::list and plf::colony - now use constexpr at all type-traits-determined if statements (plus a couple of other places) when C++17 is available/specified. In some scenarios I found this also reduces code size and increases performance, depending on the functions the program uses. Yell out if you get any bugs.
I've been toying with the idea of retaining some or all memory blocks within colony when they become empty, then simply reusing them when the rest of the blocks become full. The problem with this is that it adds a bit of code, fills up your memory faster, and doesn't have any performance advantages. I've benchmarked this on core2 and haswell, and basically the best, most optimized solution I could come up with (which was - only retain blocks of maximum size, or the last block in the chain), just scraped by as being equal to the version of colony without block retention.
Unfortunately, that performance gain you get from not deallocating and then reallocating later, is pretty small when compared to the small amount of extra code and handling necessary to store the list of empty groups. So what's my recommendation? Well, use an allocator. Colony, like most containers, takes an allocator as a template argument, so you can use a pool allocator or similar to reuse old memory space rather than freeing to the system all the time. Of course, the allocator has it's own (small) amount of overhead, but it's better than bogging colony down with the code that 90% of people won't use.
For anyone who's interested, the benchmark results are here. Peace out.
Here. The biggest noticable difference, as the previous benchmarks were done with colony v4.00, is erasure. Big, big improvements there.
Also, plf::timsort has been removed as fairly major changes are coming through for the original gfx::timsort and the changes I made to the code are not substantial enough to justify maintaining a fork. Instead the original non-forked project, gfx::timsort is now supported internally in plf::colony and plf::list, and will be used instead of std::sort whenever the header for that code is included before the colony/list header in any project. However, as always, in most cases you should stick to using std::sort, except in the areas where timsort excels (sequences which are already partially sorted, or partially/fully reversed).
In addition, all containers have had their compiler/library detection code updated to better reflect the status of libc++ (should not disable type trait support when using clang + libc++ now). Reverse() within plf::list has been simplified/optimized, with the following results on haswell:
Where erasures have occured prior to reversal, up to 38% performance increase for lower numbers of elements and 7% performance increase on average.
Where erasures have not occured prior to reversal, variable results but no change to performance on average. For between 10 and 120 elements, average roughly 8% performance increase, between 120 and 1000 elements average 3% performance loss, for between 1000 and 100000 elements on average there is no change to performance.
Interestingly for me, std::list's reverse() performance got one hell of a lot better between whatever version of libstdc++ GCC 7.1 and 8.2 use respectively. At 7.1, plf::list was ~492% faster than std::list's reverse. Now, even though plf::list's reverse() has gotten faster, for gcc 8.1 it's only 70% faster on average than std::list. I'd have to go back and re-run the tests to make sure this wasn't some benchmarking mistake, but eh - better things to do...
Tests in question were run on a haswell processor, under GCC 8.1.
Referencer tests (multiple collections of interlinked small structs): Widely variable performance differences depending on number of elements, but on average 2% performance gain for higher modification rates and 0.8% performance loss for lower modification rates.
General use tests (insertion, erasure and iteration on the fly measured over time): Up to 6% performance gain for high modification rates and numbers of elements under 19000. Average gain of 0.5%.
Raw tests:
Large struct: no change to insertion or iteration, 3% average performance improvement for erasure with up to 9% improvement for very large numbers of elements.
Small struct: no change to insertion or iteration, for erasure there was up to 3% performance decrease for numbers of elements under 30, up to 5% performance improvement for numbers of elements over 200000, on average no significant difference.
Int: no change to iteration, insertion: up to 9% worse performance for under 150 elements, up to 25% better performance for more than 130000 elements, erasure: 2% worse performance on average.
Double: no change to iteration, widely variable results for insertion, on average 2% worse, for erasure more consistently 1% better on average.
Char: 45% faster iteration on average (not sure how that works but I imagine bumping the minimum alignment width to 2 * sizeof(short) ie. 32-bits has something to do with it), widely variable results for insertion but 1% slower on average, 2% faster erasure on average.
The datasheets for the results above are here.
Basically colony is usually most effective with the default unsigned short skipfield type - I've come across no benchmark scenarios yet where unsigned int gives a performance advantage, even for vast numbers of elements. There's a number of reasons for that - cache space saving, the removal of memory blocks when they become empty and the skipfield-type-imposed limitation on the size of those memory blocks and subsequent statistical likelihood of them being empty. Basically, the skipfield patterns used for colony require that the number of elements per block cannot be larger than the maximum size representable by the skipfield type ie. 65535 for unsigned short, 255 for unsigned char. But, sometimes you only want a small number of elements - under 1000 to be specific. Where this is the case, you may want to swap to using unsigned char instead of unsigned short for your colony skipfield type.
Skipfield type is the second parameter in the colony template, so plf::colony<small_struct, unsigned char> temp; will give you an unsigned char skipfield type for your container instance.
How does this work out performance-wise? Well, it varies from CPU to CPU. For core2 you can sometimes get a 2%-20% performance advantage over unsigned short, depending on the number of elements you have and ratio of insertion/erasure-to-iteration for your container usage. Very high levels of modification don't benefit significantly from an unsigned char skipfield regardless of number of elements. On ivy bridge, there is seldom a performance advantage for using unsigned char. Mostly it is a performance detriment.
Here's the results for Haswell (GCC 8.1) when using unsigned char skipfields instead of unsigned short skipfields:
Referencer tests (multiple collections of interlinked small structs): Up to 500% (!) loss for > 65000 elements, high modification rates, on average 26% loss. Up to 5% gain for numbers of elements under 1000 and low modification rates.
General use tests (insertion, erasure and iteration on the fly measured over time): Up to 4% loss for large numbers of elements. Average loss of 2%.
Raw tests (large struct and int not measured):
Small struct: up to 10% loss for iteration, average 6%. Widely variable results for insertion, on average 4% gain. Erasure 1% loss on average.
Double: up to 14% loss for iteration, average 3%. Widely variable results for insertion, on average 1% loss. Erasure 3% loss on average.
Char: up to 10% gain for iteration, average 6%. Widely variable results for insertion, on average 3% loss. No change for erasure.
Memory usage is a different story again and is of course consistent across CPUs. Across the board, in terms of the benchmarks I was running (with small structs around 48 bytes) the amount of memory saving going to an unsigned char skipfield was about 2% for under 1000 elements. Of course this will be more if you're storing a scalar type of some sort, and hence the skipfield takes up a larger part of the overall memory cost. But once you get up to larger numbers of elements, you can sometimes end up saving 50% memory overall - this is not due to the skipfield type per se, merely due to the effect it has on limiting the size of the element memory blocks. You can also accomplish this with the change_block_sizes() functions. Since with an unsigned char skipfield type you can't have a memory block larger than 255 elements, this means that your unused capacity in a new memory block is never going to be more than 254 elements. However, with an unsigned short skipfield type the unused space in a new memory block could be up to 65535 elements wide. This can be a significant amount of memory if your element type is large.
It should be noted that the largest performance decrease above 1000 elements when using a skipfield type of unsigned char instead of unsigned short, was 2% on core2 and 7% on ivy bridge. And the bulk of the performance increases for using an unsigned char type occured on core2 and under 256 elements. Hence my recommendation is: if you want performance, stick with the default skipfield type for the most part. But depending on your CPU and context, for under 1000 elements you may or may not get a significant performance increase using an unsigned char skipfield type. And if your focus is on saving memory, change to unsigned char and/or change your minimum and maximum memory block sizes.
To throw an additional spanner into the works, I decided to customise a version of colony for small sizes and unsigned char skipfields, so that the size_type and difference_type typedefs used throughout the template did not allow for more than 32767 elements in the colony total. Basically this is to see whether a specialized 'small colony' container would be useful as opposed to having one container with a template parameter for the skipfield. I found that this was not worthwhile - the performance saving was generally 0 while the memory saving was between 4% and 2% when the number of elements was under 40, and less than 1% if the number of elements was over 40 (some variability but I put this down to undiagnosed bugs arising from not static_cast'ing the new size_types in all circumstances - and I don't have time or interest in pinning it down). Adding that to the additional overhead required to keep two versions of colony maintained, it turned out to be a worthless gesture, but one worth trying at least.
The datasheets for the results above are here.
~11 years ago a made a film called o2 in C++ - rather, I generated the visuals in C++ by using SDL and just breaking things. Mostly I used sin & cos & rgb values (which is immediately apparent when you watch it). Sometimes I ended up using the values left over in memory from previous programs to accidentally make random stuff (like in the opening sequence) - I'm not actually sure if you can still do this on modern OS's (some of my experiences suggest not).
Anyway, this footage was cut together and I used it to make a 15-minute music video comprising five of the songs from this electronic album. Unfortunately the video seems to be a litmus test for how awful your video codec is. Divx (remember that?) couldn't compress it at all, Xvid did the best job in 2007, but it took several years before h264 became widespread enough (and the encoders for it good enough) so I could actually make a decent non-lossless compress of the film.
Unfortunately youtube dials down the bitrate hard enough that even with a great encode, the video still turned it into an unviewable sea of shifting mpeg blocks. Even when upscaled to 720p with lanczos, the bitrate was not sufficient to avoid the clustertruck of minecraftification. But lately I've been wondering if it was ever going to be possible to make this viewable online. Luckily, I discovered Waifu2x. Waifu2x is an attempt to use a neural net to upscale anime videos & pictures using sample sets to tell the upscaler what the result should look like at a higher resolution. It is extremely precise and crazy. Plus, Super-Nerdcore.
So, I thought I'd give that a shot - it needs an nvidia GPU and CUDA and A BUNCH OF CUDA STUFF but it all works well. The process was surprisingly easy, once I found the right tools. Anyway, I upscaled this film from it's original SD resolution to 4k - and it worked. If anything, it made the upscaled film look better. So, I finally uploaded it to youtube, it converted to 1080p (the film's still in 4:3 aspect ratio, and youtube don't like that for 4k), and it's still not great - though sufficiently more viewable due to the higher bitrate afforded by 1080p, there's still quite a lot of minecraftification happening. So instead, here's a 3GB download of the film at 4k: enjoy.
For reference, the lossless-compressed (UTvideo) version of the film is 106GB.
As mentioned on the colony page and in countless as-yet unaccepted standards proposals, any colony implementation is structured around 3 aspects:
In colony v4.5 the third of these was changed from a stack of memory locations to a series of per-memory-block free lists. In colony v5.0 both the second and third change; the third changes from per-memory-block singly-linked free lists of erased element locations, to per-memory-block doubly-linked free lists of skipblocks. A skipblock, in colony terminology, refers to any sequence of contiguous erased elements - including sequences of only one erased element. By recording skipblock locations instead of singular erased element locations, we improve performance by decreasing the number of skipfield nodes which need to be altered upon erasure or insertion. But, this also enables a further improvement.
By only storing skipblocks we are able to change the second aspect above (the skipfield) to the Bentley pattern, instead of using the Advanced Jump-counting skipfield pattern. Without going into it in great detail, the Bentley pattern is a refinement of the simple variant of the jump-counting skipfield pattern. It does not require the middle nodes of a skipblock to be updated upon changes to the skipblock - however, only the beginning and end nodes of the skipblock may be changed. But since we're only keeping records of skipblocks instead of individual erased nodes, this means we can choose which erased element within the skipblock to reuse, and only change a beginning or end node.
In addition, reusing the beginning or end node of a skipblock (current implementation reuses the beginning because of a benchmarked performance advantage in terms of multiple insertions and thus reusing multiple sequential nodes from left to right instead of from right to left) is advantageous for iteration performance; reusing a middle node means splitting a skipblock in two, increasing the overall number of skips during iteration.
Without writing a paper here (I am writing a paper - just not right here), the simple upshot of this is that all skipfield updates for single insertions and erasures are now O(1) amortized, and skipfield updates for multple insertions/erasures are O(1) per-memory-block affected - as opposed to previous versions where all these were undefined in terms of time complexity. Insertion, erasure and iteration become faster in the context of multiple erasures and insertions over time; as the number of skipblocks - and the subsequent number of jumps required during iteration - is reduced substantially.
A lingering question might be, why the change from a singly-linked per-memory-block free list to doubly-linked? Well, turns out if you're storing/reusing singular erased element locations, singly-linked is fine - you make the newly-erased element the new head of the free list and point it's 'next' index to the previous head - regardless of scenario. However if you're storing whole skipblocks, when you reach the scenario where you're erasing an element that is directly between two skipblocks, you have to join the skipblocks and remove the record of one of the skipblocks from the free list - which requires either:
Across multiple benchmarks the second solution works out to be faster as the first requires jumping all over the memory block in the case of many non-contiguous erasures and subsequently many skipblocks. When the elements in question are large, this can have huge cache effects, since the free list index info is stored within the erased element's memory space, not it's skipfield node. The performance cost of having to update and maintain both a previous and next index is minimal by contrast.
A side-effect of this is that elements are now over-aligned to (sizeof(skipfield type) * 2) (or the type alignment if that is larger). So, assuming the default skipfield type of unsigned short, a colony storing char or short has that type padded to 32bits (assuming unsigned short is 16 bits on that platform), in order to store both a next and previous index when an element gets erased and becomes part of a free list. The performance cost of this is minimal, the storage cost is larger (though not as large as it was before v4.5 when colony was still using a pointer stack), but, colony was never designed for small types - if you store chars or shorts in a colony you are already wasting space due to the skipfield node being larger/as large as the element itself. So not a huge loss from my perspective.
So yeah - big update, big change, for the better. Hope everyone gets some use out of it!
I did another guest post on Arne's blog about the dangers of letting area-specific 'elegant' solutions dominate a language.
The next time someone tells you that std::fill_n or std::fill is as fast as memset, get them to benchmark it.
Xubuntu 18, Core2Duo E8500 CPU, GCC 7.3
Results in release mode (-O2 -march=native):
=============================================
2018-07-10 21:28:11
Running ./google_benchmark_test
Run on (2 X 3800.15 MHz CPU s)
CPU Caches:
L1 Data 32K (x2)
L1 Instruction 32K (x2)
L2 Unified 6144K (x1)
-----------------------------------------------------
Benchmark Time CPU Iterations
-----------------------------------------------------
memory_filln 16488 ns 16477 ns 42460
memory_fill 16493 ns 16493 ns 42440
memory_memset 8414 ns 8408 ns 83022
Results in debug mode (-O0):
=============================
-----------------------------------------------------
Benchmark Time CPU Iterations
-----------------------------------------------------
memory_filln 87209 ns 87139 ns 8029
memory_fill 94593 ns 94533 ns 7411
memory_memset 8441 ns 8434 ns 82833
Results in -O3 (clang at -O2 is much the same):
================================================
-----------------------------------------------------
Benchmark Time CPU Iterations
-----------------------------------------------------
memory_filln 8437 ns 8437 ns 82799
memory_fill 8437 ns 8437 ns 82756
memory_memset 8436 ns 8436 ns 82754
#include <cstring> #include <algorithm> #include <benchmark/benchmark.h> double total = 0; static void memory_memset(benchmark::State& state) { int ints[50000]; for (auto _ : state) { std::memset(ints, 0, sizeof(int) * 50000); } for (int counter = 0; counter != 50000; ++counter) { total += ints[counter]; } } static void memory_filln(benchmark::State& state) { int ints[50000]; for (auto _ : state) { std::fill_n(ints, 50000, 0); } for (int counter = 0; counter != 50000; ++counter) { total += ints[counter]; } } static void memory_fill(benchmark::State& state) { int ints[50000]; for (auto _ : state) { std::fill(std::begin(ints), std::end(ints), 0); } for (int counter = 0; counter != 50000; ++counter) { total += ints[counter]; } } // Register the function as a benchmark BENCHMARK(memory_filln); BENCHMARK(memory_fill); BENCHMARK(memory_memset); int main (int argc, char ** argv) { benchmark::Initialize (&argc, argv); benchmark::RunSpecifiedBenchmarks (); printf("Total = %f\n", total); getchar(); return 0; }
Note: The for-loop counting the array contents is necessary for the benchmark loops not to get optimized out by clang (which detects that the arrays are unused and removes them).
So I took part in an exercise to try and understand google benchmark, as a small part of the larger task of understanding the google toolchains en generale. Google documentation is... lets say, "sparse", sometimes inaccurate and typically lacking in reasonable explanations for newbs, so it took quite a bit of searching to understand what the different macros were doing. Final result: figured out they were running each process a certain number of times to get an estimate as to how many iterations would be necessary to achieve statistically-meaningful results, then running the benchmark post-warmup. Plan to submit a merge request to the google benchmark docs, at some point when I have time.
At any rate, I was surprised to find the insertion (push_back) results did not match my own benchmarks in windows (I was in this case running goog-bench on xubuntu 18 on a core2). Deque, bless it's little libstdc++ heart, was outperforming it by a factor of 2 - which was unusual. For 100000 insertions, libstdc++'s deque should've been performing approximately 781 allocations per-run, as it allocates memory blocks in 512-byte chunks; whereas colony, with it's memory block growth factor of 2, should've performed approximately 12 allocations total. Memory allocation being an expensive operation in general, under my windows benchmarks colony had largely outperformed deque in terms of insertion. So the only conclusion I could come to...
... was that windows memory allocation sucks. I fired up Win7, checked my libstdc++/gcc version numbers (gcc 7.3 x64 on both linux and windows/mingw), downloaded python, cmake, google benchmark & test, and recompiled the test under nuwen mingw. Sure enough, same GCC, same optimization flags (-o2 -march=native), same compilation under Codelite, but now colony outperformed deque by a factor of 2. I re-ran tests both on linux and windows, just to make sure there weren't any fluke values, but it was consistent. BTW, all speedstep / power-saving / services / AV /networking / UAC / etcetera / etcetera / etcetera are disabled on both setups. I also tested a box with an Ivy bridge CPU and Windows 10, and the results were exactly the same. So there you have it; memory allocation under windows is breathtakingly slow. But that wasn't the only surprise. Take a look at the comparitive results below:
--------------------------------------------------------------------------
Benchmark Time CPU Iterations
--------------------------------------------------------------------------
benchmark_colony_creation 1 ns 1 ns 897430145
benchmark_deque_creation 128 ns 128 ns 4985723
benchmark_vector_creation 1 ns 1 ns 897430145
benchmark_colony_insertion 281589 ns 275333 ns 2493
benchmark_deque_insertion 546001 ns 546003 ns 1000
benchmark_vector_insertion 736900 ns 736903 ns 1122
benchmark_colony_erasure 713045 ns 713048 ns 897
benchmark_deque_erasure 183300495 ns 183301175 ns 4
benchmark_deque_erasure_remove_if 336472 ns 328826 ns 2040
benchmark_vector_erasure 312000513 ns 312002000 ns 2
benchmark_vector_erasure_remove_if 260000 ns 260002 ns 2640
benchmark_colony_iterate_and_sum 121685 ns 121686 ns 6410
benchmark_deque_iterate_and_sum 95949 ns 95949 ns 7479
benchmark_vector_iterate_and_sum 69534 ns 69535 ns 8974
--------------------------------------------------------------------------
Benchmark Time CPU Iterations
--------------------------------------------------------------------------
benchmark_colony_creation 1 ns 1 ns 885853600
benchmark_deque_creation 42 ns 42 ns 16841287
benchmark_vector_creation 1 ns 1 ns 886048673
benchmark_colony_insertion 427091 ns 427091 ns 1639
benchmark_deque_insertion 253210 ns 253210 ns 2764
benchmark_vector_insertion 700716 ns 700709 ns 997
benchmark_colony_erasure 743468 ns 743458 ns 939
benchmark_deque_erasure 94806854 ns 94806240 ns 7
benchmark_deque_erasure_remove_if 297223 ns 297222 ns 2355
benchmark_vector_erasure 96288165 ns 96288299 ns 7
benchmark_vector_erasure_remove_if 169655 ns 169655 ns 4100
benchmark_colony_iterate_and_sum 120794 ns 120793 ns 5801
benchmark_deque_iterate_and_sum 95539 ns 95539 ns 7300
benchmark_vector_iterate_and_sum 69133 ns 69133 ns 10100
Note: Both remove_if and non-remove_if erase benchmarks randomly remove 1 in every 8 elements from the total in the container.
You can see non-remove_if erasure (erasing randomly during iteration) in both vector and deque is 2-3x as slow under windows compared to linux - this indicates that, not only are memory Allocations slower, but also memory Copies are slower. However this particular result did not show up on the Win10/Ivy Bridge setup (where the non-remove_if erase results were comparitively equal between linux and windows), indicating that either Win10 is better at memory copies or windows is better at handling memory copies on Ivy Bridge CPUs than Core2's. The "creation" benchmarks (instantiate an instance of a template, check it's size, then destroy it) show the initial allocation/deallocation of deque (unlike vector and colony, libstdc++'s deque implementation allocates it's first memory block upon instantiation instead of upon first insertion) was roughly 4x slower in windows! Lastly, vector erasure with remove_if is almost twice as fast under linux as opposed to windows.
So how did windows memory system get so inefficient? Or perhaps a better question, how did linux's memory management get so efficient? Perhaps that's the right question. Millions of contributors worldwide with an emphasis on performance and stability not "new features" or shiny interfaces, probably. One might ask, why not test this under MSVC? Well, I already did that with my regular benchmarks, and they showed much the same results as mingw, only slower, so that's probably not necessary. Given that colony was initially designed for game engines and games almost universally are designed for windows on the desktop/laptop, this is not a great loss for colony, at least in it's original use-case. And of course it's non-remove_if erasure results are still the best out of all containers. The last thing to note from these results is that colony insertion is noticably slower under linux than under windows. I'm not sure why this should be, on the same compiler, same processor etc. So there's something to look into there.
For anyone wanting to run these benchmarks themselves, here is the code.
UPDATE 19-06-2018: I tried doing a simple google benchmark with memory allocation/deallocation only. This was consistent with the findings for the allocation/deallocation of deque - about 37ns for Xubuntu (GCC) and about 176ns for Windows 7 (mingw-GCC - ~220ns under MSVC2017). The results were almost exactly the same on the Ivy Bridge/Win10 setup. In addition I also tested memset, which was 20-30% slower on windows, depending on the CPU/platform. The .cpp for this test has been included in the zip above.
| Operation | Char | Int | Double | Small Struct | Large Struct |
| Insert | +2% | +3% | +5% | +4% | 0% |
| Erase | +0% | +26% | +13% | +10% | +5% |
| Iterate | -43% | -1% | 0% | 0% | 0% |
The negative result for char iteration is due to the fact that the char type has to be artificially-widened to the same size as the skipfield type (unsigned short) in order for the free list mechanism to work in v4.5 (v4.0 used a pointer stack). This can be mitigated by using unsigned char for the skipfield type in colony's template arguments (only really useful for small collections < 1024 elements).
+35% average, +58% max (low number of elements), +20% min (high number of elements)
Low-modification: +1%,
High-modification: +2.5%
+2%, increased lead vs packed-array types
So here's the thing. colony 4.5 is a lot faster than it's predecessor, due to ditching a stack for erased locations and employing per-memory-block free-lists (plus a global intrusive list of blocks-with-erasures) instead. It also uses less memory, and enables erase to be more exception-safe due to a lack of allocation. Also it supports overaligned types! Here's how that all came about:
Someone at the container-focused C++ committee meeting in Jacksonville said colony shouldn't use a stack for erasures because that could create an allocation exception upon expanding the stack. Now that's partially true, erase can throw exceptions anyway because (a) a destructor might throw an exception - for example, if an object has a file open and can't close it on destruction for some reason - and (b) an invalid/uninitialized iterator could be supplied to the function. Regardless, it's a good point, and I started looking into how to make that not happen. I came back to an old idea I'd had for using per-memory-block free lists instead of a stack for recording erased/reusable locations for future insertions.
The main reason I didn't go with that in the first instance was because I didn't really understand how explicit casting works in C++; originally I thought that I would need to use unions to make a free list work in this case, which don't support basic object-oriented functionality like constructors etc. When in reality, if you have a pointer to something in C++, you can reinterpret_cast anything to it, provided you don't overflow bit boundaries and mess something up. I don't particularly see why C++ doesn't allow one to do this with just regular objects, but I'm sure there's some eldritch reasoning.
The second reason I thought it wouldn't work was because free lists typically utilize pointers, and while fast, pointers are large(ish) - so using colony with scalar types would mean padding them to 64-bit most of the time - not cool man!!! Because of my experiences writing plf::list, I was more experienced with thinking through this approach with pointers in mind. But, I realised eventually that since the free list is per-block I could use indexes relative to the start of that memory block, instead of pointers, and that these indexes only had to be of the same type as the skipfield (unsigned short by default) - so this would work fine for everything except char - where the type would have to be padded to the size of unsigned short. Not a huge loss since I don't see people using char with colony much, if at all... (and people can always change the skipfield type to unsigned char for small collections and get better performance anyway)
So what I wound up with was (a) per-block free-lists of indexes via reinterpret_cast'ing of the 'next' free list index into the current index's erased element's memory space, and (b) per-block free list heads (also an index) and (c) a global intrusive singly-linked list of all memory blocks which have erasures (with a global list head). Pretty cool. No additional memory allocations necessary to record the erasures. No wasted memory (asides from the extra per-block head, and 'next' pointer for the global groups-with-erasures list). Better performance due to a lack of allocations upon erasure. Lastly, no having to process the stack to remove erased locations when a memory block is freed to the OS. When you get rid of a memory block now, it's free list of course goes with it- so all you have to do is remove it from the global intrusive list of memory blocks with erasures (pretty quick).
The nice thing about this exercise is how easy it was - I didn't expect the upgrade to be anything but a bundle of heavily-bugged freak-outs, but the initial work was done in about 3 hours, while the rest of it - fixing up capacity(), setting up padding for char under C++11 etc, finding the edge-cases, optimizing, took about a week or so. The side-benefit of setting up for artifically widening the type padding when the skipfield type is larger than type T ended up being support for over-aligned types, which is also cool. I don't forsee a hell of a lot of use of SIMD with colony (for the reasons stated here) but at least it's more possible now.
By the way, rules for colony behaviour when the skipfield type is larger than the element type are as follows:
Also, colony is now exactly three years old since first release! ... Happy Birthday?!
For 30 years, comp sci teachers have been trying to educate programmers out of using meaninglessly terse variable, class and object names. But now, the battle appears to be being lost, as too many programmers are failing to recognise that typenames are not an exception.
For the sake of argument, let's say I'm stupid. I like to write code like "int i = 10;". 'i' has an inherent meaning. Sure, I can look at the code and infer the meaning, but that increases cognitive load - or maybe I'm the kind of programmer that takes a perverse pride in my ability to rapidly infer meaning out of meaningless code. If the latter, I'm even dumber than I thought because I failed to realise that those brain cycles could be better spent on other things.
Let's separate this out into 4 concepts: "terseness", "aesthetics", "readability" and "meaningfulness". Compare and contrast the following two paragraphs:
"Colony is a container with fast insertion and erasure times, which doesn't invalidate pointers to non-erased elements."
versus
"Colony is a container with fast insertion and erasure times, which doesn't invalidate pointers to non-erased elements. This makes it beneficial for programs where there is substantial interlinking between different sets of elements and where elements are being erased and inserted continuously in real time."
The first paragraph is more terse. Aesthetically, there is no substantial difference between the two, unless you aesthetically prefer shorter writings - this is because aesthetics are largely subjective and meaningless, typically based more on familiarity than logic. The readability of both paragraphs is the same - it's just that the second paragraph makes you read more. But the meaningfulness of the second paragraph is greater. The second sentence in the paragraph *can* be inferred from the first, but doing so (a) increases the cognitive load of the reader and (b) increases the chance they might create an incorrect inference in their own minds, purely through the flexibility of the human brain and thinking.
So we can see that readability and aesthetics do not necessarily have anything to do with terseness or meaningfulness, but terseness and meaningfulness can be opposed. And while there are certainly ways of writing which are both more terse and more meaningful at the same time, often there's a tradeoff. Many programmers appear to side on the 'fewer keystrokes' way of thinking, but this is a mistake if you understand that code is always read more than it is written, even if it's a program that only you yourself will ever read. Going over and over your code is made more tedious and more time-consuming if you waste cycles decrypting the semantics of it.
For this reason, teachers of comp sci will tell you to give your variables and classnames real names, ones which indicate their purpose. Even if "i" is a counter in a loop, just calling it "counter" negates other possible meanings of the variable, and makes the code more meaningful as a result. So why, now, are programmers in multiple languages opting for code similar to "auto i = 0;"?
Let's, again, break this down into multiple categories. The two I'm familiar with are "type cascading" and "terseness". We already understand how terseness is problematic, but to go into more depth, look at the following two sections of C++ code:
for (auto i = some_stuff.begin(); i != some_stuff.end(); ++i)
{
// do stuff with 'i'
}
vs
for (vector<int>::iterator current_stuff = some_stuff.begin();
current_stuff != some_stuff.end(); ++current_stuff)
{
// do stuff with 'current_stuff'
}
So, we're forcing the reader to infer three things in the first section: the type of 'some_stuff', the type of 'i' (iterator or pointer to an element, , presumably) and the meaning of 'i' in the enclosed code. Now, if the loop is reasonably short and uncomplicated, perhaps the omission of a meaningful name for 'i' is not that important - it's right there, after all. If the loop contains a lot of code however, 'i' makes it less meaningful, particularly if there are other meaningless variable names like 'j'. But the worse of the two is the type inference. Not only does the reader have to infer the type of 'i' by going back through the code and finding out what 'some_stuff' refers to, but they must now also infer whether 'i' is an iterator or a pointer.
So while we save keystrokes with the first section, and from a certain point of view it could be considered more aesthetically " pleasing", it is also much more meaningless, and creates more cognitive load, rather than less. This is bad code: not because it's terse, but because you waste more human energy and brain cycles in the code's lifetime.
Type-cascading is another anti-pattern. If you're using 'auto' across multiple functions which call each other in a heirarchy, where the initial type is specified at point 'A', all that means is that at point 'B' you have to navigate back through multiple function calls to find the actual type - wasting time and human energy. It's something that can be done more meaningfully using typedef's, but overall in terms of code meaningfulness should be avoided, where possible. Templates are an example of useful type cascading, but it can be taken to extremes, and when it does, the signal-to-noise ratio becomes strong.
Now, I'm not saying 'auto' is incredibly worthless or that there couldn't be some scenario where it's even necessary - but the way it's used in general in C++ is wrong - it increases terseness at the cost of meaningfulness, and sometimes it doesn't even increase terseness (see 'int', 'char')! It comes across to me as a gimmick, something to make the language more attractive to programmers who're used to the same feature being present in another language. But it's a mistake to think that in all those years promoting meaningful naming in code, that we should leave type definitions out of that equation.
Addendum: I wrote a related article called "Terseness: how little is too much?" on Arne Mertz's blog, which explores the concept of meaningful naming in general.
Contact: 
plf:: library and this page Copyright (c) 2026, Matthew Bentley