Home
PLF C++ Library - plf::colony
Introduction
plf::colony is the highest-performance C++ template-based data
container for high-modification scenarios with unordered data. All
elements within a colony have a stable memory location, meaning that
pointers/iterators to non-erased elements are valid regardless of
insertions/erasures to the container. Specifically the container
provides better performance than other std:: library containers when:
- Insertion order is unimportant,
- Insertions and erasures to the container are occurring frequently in
realtime i.e. in performance-critical code, and/or
- Insertions and erasures to the container may not invalidate pointers/iterators to non-erased elements.
While the benchmarks later on the page are a better way to get a feel
for the performance benefits, the general performance characteristics are:
- Singular, unordered insertion: better than any std:: library
container.
- Erasure: better than any std:: library container.
- Iteration:
better than any std:: library container capable of preserving
pointer/iterator validity post-erasure/insertion (e.g. map, multiset,
list). Some variance here for scalar types and between different CPUs
obviously. Where pointer/iterator validity is unimportant, better than
any std:: library container except deque and vector.
As explored further in the benchmarks there are some vector/deque modifications
which can outperform colony during iteration while maintaining pointer validity, but at a
cost to usability and memory usage and without colony's insert/erasure
advantages. Colony's other advantages include freeing and/or recycling
of unused memory on-the-fly, guaranteed stability of
pointers/references/iterators to non-erased elements (which makes
programming with containers of inter-related data structures faster and easier),
and broad cross-compiler support.
A colony's structure can be reasonably compared to a "bucket array",
where each element location can be emptied and skipped over. Unlike some bucket
arrays it does not use keys or id's, and it iterates faster due to the use of an advanced skipfield type (previously a high complexity jump-counting pattern, now a low complexity jump-counting pattern) instead of a
boolean field, and frees or recycles unused memory from erased elements
on-the-fly. It was initially developed predominantly for game
development, so is designed to favour larger-than-scalar-type (structs/classes of
greater-than 128 bits total) performance over scalar-type (float, int, etc)
performance. It supports over-aligned types.

Colony is the container upon which the current standards proposal
for "std::hive" is based. The name and some functionality has diverged
as a result of colony having to cater for C++03/11/etc containers, some functions being seen as unnecessary and
the committee viewing colony as an inappropriate name for various
reasons. A reference implementation for hive is here (C++20 and upwards only).
Motivation
Note: initial motivation for the project came from video game engine
development. Since this point it has become a more generalized container.
Nevertheless, the initial motivation is presented below.
When working on video game engines we are predominantly dealing with
collections of data where:
- Elements within data collections refer to elements within other data
collections (through a variety of methods - indices, pointers, etc). An
example is a game entity referring to both a texture object and collision
blocks, as well as sound data. These references must stay valid throughout
the course of the game/level. For this reason, any container (or use of a
container) which causes pointer or index invalidation can create
difficulties or necessitate workarounds.
- Order is unimportant for the most part. The majority of data collections
are simply iterated over, transformed, referred to and utilized with no
regard to order.
- Erasing or otherwise removing or deactivating objects occurs frequently
in-game and in realtime (though often erasures will be implemented to occur
at the end of a frame due to multithreading concerns). An example could be
destroying a wall, or a game enemy. For this reason methods of erasure
which create strong performance penalties are avoided.
- Creating new objects and adding them into the gameworld on-the-fly is
also common - for example, a tree which drops leaves every so often, or a
quadtree.
- We don't always know in advance how many elements there will be in a
container at the beginning of development, or even at the beginning of a
level during playback - an example of this being a MMORPG (massively
multiplayer online role-playing game). In a MMORPG the number of game
entities fluctuates based on how many players are playing, though there may
be maximum capacity limits. Genericized game engines in particular have to
adapt to considerably different user requirements and scopes. For this
reason extensible containers which can expand and contract in realtime are
usually necessary.
- Depending on the complexity and scope of any given game, we can be
dealing with anywhere between 10 and 100000 objects in a given area. We are
not typically dealing with the types of capacities necessitated by
large-scale mathematical or statistical applications.
- For performance reasons, memory storage which is more-or-less contiguous
is preferred. Lists, vectors of pointers to dynamically-allocated objects,
and maps as implemented in the standard library are unusable.
- Memory wastage is avoided, and in particular, any container which
allocates upon initialisation tends to be avoided as this can incur
purposeless memory and performance costs.
To meet these requirements, game developers tend to either (a) develop their
own custom containers for given scenario or (b) develop workarounds for the
failings of std::vector. These workarounds are many and varied, but the most
common are probably:
- Using a boolean flag (or similar) to indicate the inactivity of an object
(as opposed to actually erasing from the vector). When erasing, one simply
adjusts the boolean flag, and when iterating, items with the adjusted
boolean flag are skipped. External elements refer to elements within the
container via indexes rather than pointers (which can be invalidated upon
insertion).
Advantages: Fast erasure.
Disadvantages:
Slow to iterate due to branching and unpredictable number of skipfield
checks between any two non-skipped elements.
- Utilising a vector (or array) of data with a secondary vector (or array) of indexes. When
erasing, the erasure occurs in the vector of indexes, not the vector of
data, and when iterating, one iterates over the vector of indexes, then
accessing the data from the vector of data via the index.
Advantages: Faster iteration.
Disadvantages: Erasure still incurs some reallocation cost, can increase
jitter. Insertion comparatively slow.
- Combining a swap-and-pop mechanism with some form of dereferenced lookup
system to enable contiguous element iteration (sometimes known as a 'packed
array', various other names including "slot map"). In this case when erasing we swap the
back element from the vector of elements with the element being erased,
then pop the (swapped) back element. When iterating over the data we simply
iterate through the vector of elements. However to maintain valid external
links to elements (which may be moved at any time) we must also maintain a
stable vector of indexes (or similar) and update the index numbers
corresponding with the element being erased and the element being moved. In
this case external objects referring to elements within the container must
store a pointer or index to the index for the element in question. There are many
variants of this method. It is more useful when the
container's data is mostly being iterated over with fewer references to the
individual elements from outside objects, and less insertion/erasure.
Advantages: Iteration is at standard vector speed.
Disadvantages: Erase could be slow if objects are large and swap cost is
therefore large. Insertion cost is larger than other techniques. All
references to elements incur additional costs due to a two-fold reference
mechanism.
All three techniques have the disadvantage of slow singular insertions, and
the first two will also continually expand memory usage when erasing and
inserting over periods of time. The third deals better with this scenario as it
swaps from the back rather than leaving gaps in the elements vector, however
will suffer in performance if elements within the container are heavily
referred to by external objects/elements.
Colony is an attempt to bring a more generic solution to this domain. It has
the advantage of good iteration speed while maintaining a similar erasure speed
to the boolean technique described above (faster for multiple consecutive erasures), and without causing pointer
invalidation upon either erasure or insertion. It's insertion speed is also
much faster than a vector's. Memory from erased elements is either reused by
subsequent insertions or released to the OS on-the-fly. It achieves these ends
via the mechanisms described in the Intro above, examined further in the Implementation section below.
More data on the performance characteristics of the colony versus other
containers and workarounds can be found in the benchmarks
section, read below to get an understanding of the mechanics.
Implementation
Any colony implementation is defined by 3 different aspects:
- A sequence of memory blocks with a growth factor
- A skipfield to jump over erased elements (removing the need for reallocation upon erasure or insertion)
- A mechanism for remembering the locations of erased elements, in order to reuse those memory locations upon subsequent insertion
For the first of these, plf::colony uses a chained-group memory allocation
pattern with a growth factor of 2, which can otherwise be described as a doubly-linked list of element
"groups" - memory blocks with additional structural metadata, including
in this case per-memory-block Low complexity jump-counting skipfields. A growth factor of 2
tends to gives the best performance in the majority of scenarios (hence why it is
also used for the majority of vector implementations). Colony's minimum and maximum
memory block sizes can also be adjusted to suit individual use-cases. Using a
multiple-memory-block approach removes the necessity for data reallocation upon
insertion (compared to a vector). Because data is not reallocated, all
references, pointers and iterators to container elements stay valid
post-insertion.
For the second of these aspects, plf::colony uses an advanced skipfield type called a low complexity jump-counting pattern
(versions prior to v5.0 utilized the high complexity jump-counting pattern). The third aspect is currently an intrusive list of
groups containing erased elements, combined with per-group free-lists
of skipblocks. A skipblock, in colony terminology, refers to a run of
contiguous erased elements - including runs of only a single erased
element. Versions prior to v5.0 utilized free lists of individual
skipped elements, and versions prior to v4.5 utilized a stack of
pointers to individual skipped elements.
Due to a std::vector being the most widely-used and commonly-understood of
the std:: library containers, we will contrast the storage mechanisms of a
colony with that of a vector, starting with insertion:

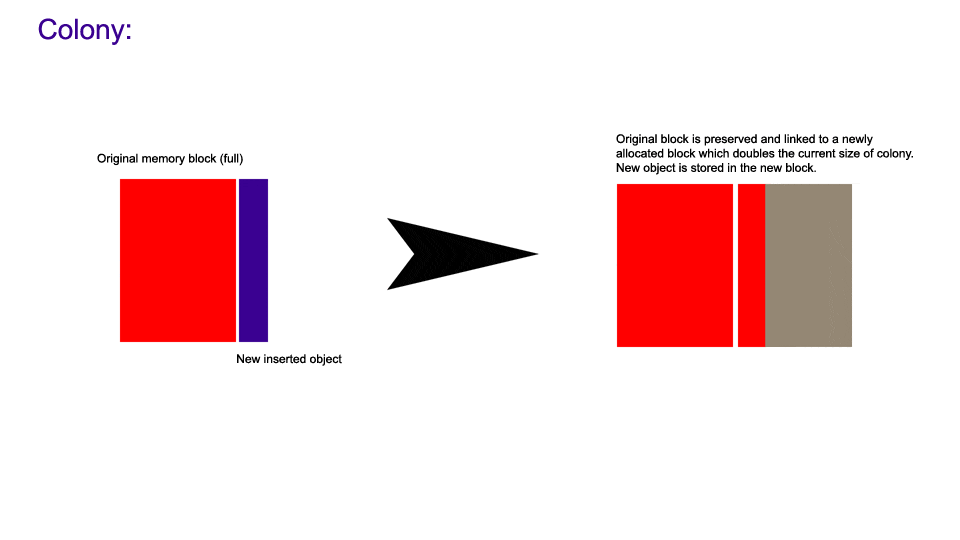
The lack of reallocation is also why insertion into a colony is faster than
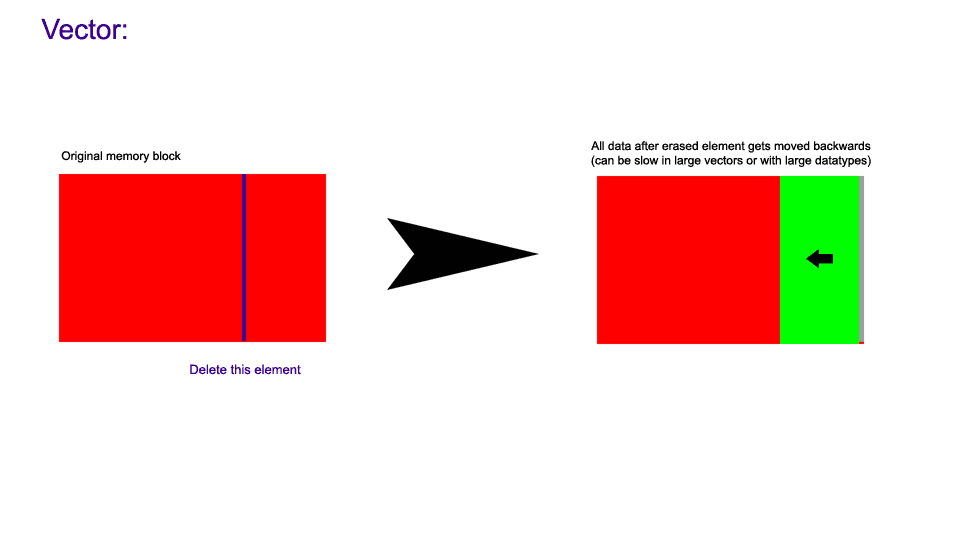
insertion into a std::vector. Now we look at erasure. When an element is erased
in a std::vector, the following happens:
When an element is erased in a colony, this happens:
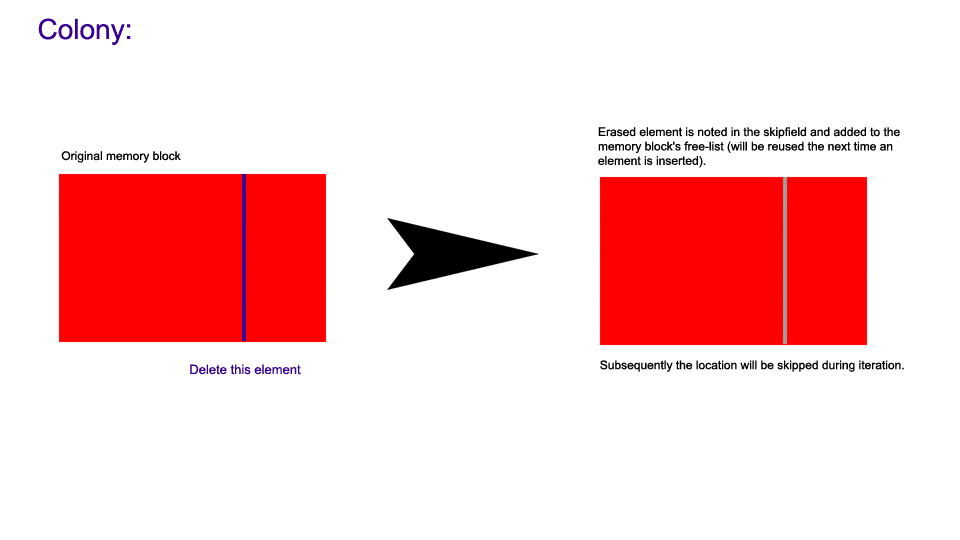
This is why a colony has a performance advantage over std::vector when
erasing.
Upon subsequent insertions to a colony post-erasure, colony will
check to see if its intrusive list of groups-with-erasures is empty (described
earlier). If empty, it inserts to the
end of the colony, creating a new group if the last group is already
full. If the intrusive list of groups-with-erasures isn't empty, the
colony takes the first group within that list and re-uses the first
memory location from the free list of skipblocks within that group. If
you erase all elements in any given group in a colony, the group is
removed from the colony's chain of groups and released to the OS, and
removed from the intrusive list of groups-with-erasures.
License
plf::colony is under a permissive zlib license. This means:
Software is used on 'as-is' basis. It can be modified and used in commercial
software. Authors are not liable for any damages arising from its use. The
distribution of a modified version of the software is subject to the following
restrictions:
- The authorship of the original software must not be misrepresented,
- Altered source versions must not be misrepresented as being the original
software, and
- The license notice must not be removed from source distributions.
Download
Download here or
view the repository
The colony library is a simple .h header file, to be included with a #include command.
In addition if you are interested in benchmarking you can also download the plf benchmark suite.
A conan package for colony is available here.
A Build2 package for colony is available here.
Function Descriptions and syntax
Colony meets the requirements of the C++ Container, AllocatorAwareContainer, ReversibleContainer
concepts. It also meets some of the requirements of a sequence container.
For the most part the syntax and semantics of colony functions are very
similar to all std:: c++ libraries. Formal description is as follows:
template <class T, class Allocator = std::allocator<T>, typename
plf::colony_priority Priority = plf::performance> class colony
T - the element type. In general T must meet the
requirements of Erasable, CopyAssignable
and CopyConstructible.
However, if emplace is utilized to insert elements into the colony, and no
functions which involve copying or moving are utilized, T is only required to
meet the requirements of Erasable.
If move-insert is utilized instead of emplace, T must also meet the
requirements of MoveConstructible.
Allocator - an allocator that is used to acquire memory to
store the elements. The type must meet the requirements of Allocator. The
behaviour is undefined if Allocator::value_type is not the same as
T.
Priority - either plf::performance or
plf::memory_use.
In the context of this implementation this changes the skipfield type
from unsigned short (performance) to unsigned char (memory_use), unless
the type sizeof is <= 10 bytes, in which case the skipfield type
will always be unsigned char (this always performs better for these
smaller types due to the effect on cache).
The skipfield type is used to form the skipfield which skips over
erased elements. The maximum size
of element memory blocks is also constrained by this type's bit-depth
(due to the
nature of a jump-counting skipfield). As an example, unsigned
short
on most platforms is 16-bit which thereby constrains the size of
individual memory blocks to a maximum of 65535 elements (the default
size is less than this, 8192 elements, for performance reasons). unsigned
short has been found to be the optimal type for performance with elements larger than 10 bytes, based on
benchmarking. However this template parameter is also used in a variety of
scenarios within functions relating to performance or memory usage. In the case of small
collections (e.g. < 512 elements) in a memory-constrained environment, it can be
useful to reduce the memory usage of the skipfield by reducing the skipfield
bit depth to unsigned char. In addition the reduced skipfield size will reduce
cache saturation in this case without impacting iteration speed due to the low
total number of elements. Since these scenarios are on a per-case basis, it is
best to leave the control in the user's hands for the most part.
Basic example of usage
#include <iostream>
#include "plf_colony.h"
int main(int argc, char **argv)
{
plf::colony<int> i_colony;
// Insert 100 ints:
for (int i = 0; i != 100; ++i)
{
i_colony.insert(i);
}
// Erase half of them:
for (plf::colony<int>::iterator it = i_colony.begin(); it != i_colony.end(); ++it)
{
it = i_colony.erase(it);
}
// Total the remaining ints:
int total = 0;
for (plf::colony<int>::iterator it = i_colony.begin(); it != i_colony.end(); ++it)
{
total += *it;
}
std::cout << "Total: " << total << std::endl;
std::cin.get();
return 0;
}
Example demonstrating pointer stability
#include <iostream>
#include "plf_colony.h"
int main(int argc, char **argv)
{
plf::colony<int> i_colony;
plf::colony<int>::iterator it;
plf::colony<int *> p_colony;
plf::colony<int *>::iterator p_it;
// Insert 100 ints to i_colony and pointers to those ints to p_colony:
for (int i = 0; i != 100; ++i)
{
it = i_colony.insert(i);
p_colony.insert(&(*it));
}
// Erase half of the ints:
for (it = i_colony.begin(); it != i_colony.end(); ++it)
{
it = i_colony.erase(it);
}
// Erase half of the int pointers:
for (p_it = p_colony.begin(); p_it != p_colony.end(); ++p_it)
{
p_it = p_colony.erase(p_it);
}
// Total the remaining ints via the pointer colony (pointers will still be valid even after insertions and erasures):
int total = 0;
for (p_it = p_colony.begin(); p_it != p_colony.end(); ++p_it)
{
total += *(*p_it);
}
std::cout << "Total: " << total << std::endl;
if (total == 2500)
{
std::cout << "Pointers still valid!" << std::endl;
}
std::cin.get();
return 0;
}
Iterator Invalidation
| All read-only operations, swap, std::swap, splice, operator=
&& (source), reserve, trim |
Never. |
| clear, operator= & (destination), operator= &&
(destination) |
Always. |
| reshape |
Only if memory blocks exist whose capacities do not fit within the
supplied limits. |
| shrink_to_fit |
Only if capacity() != size(). |
| erase |
Only for the erased element. If an iterator is == end() it will be
invalidated if the back element of the colony is erased (similar to
deque (22.3.8)).
Likewise if a reverse_iterator is == rend() it will be invalidated if the front element of the colony is erased.
The same applies with cend() and crend() for const_iterator and const_reverse_iterator respectively.
|
| insert, emplace |
If an iterator is == end() or == begin() it may be invalidated by a subsequent insert/emplace.
Likewise if a reverse_iterator is == rend() or == rbegin() it may be
invalidated by a subsequent insert/emplace.
The same applies with cend(), cbegin() and crend(), crbegin() for const_iterator and const_reverse_iterator respectively.
|
Member types
| Member type |
Definition |
value_type |
T |
allocator_type |
Allocator |
size_type |
Allocator::size_type (pre-c++11)
std::allocator_traits<Allocator>::size_type
(post-c++11) |
difference_type |
Allocator::difference_type (pre-c++11)
std::allocator_traits<Allocator>::difference_type
(post-c++11) |
reference |
Allocator::reference (pre-c++11)
value_type & (post-c++11) |
const_reference |
Allocator::const_reference (pre-c++11)
const value_type & (post-c++11) |
pointer |
Allocator::pointer (pre-c++11)
std::allocator_traits<Allocator>::pointer (post-c++11) |
const_pointer |
Allocator::const_pointer (pre-c++11)
std::allocator_traits<Allocator>::const_pointer
(post-c++11) |
iterator |
BidirectionalIterator |
const_iterator |
Constant BidirectionalIterator |
reverse_iterator |
BidirectionalIterator |
const_reverse_iterator |
Constant BidirectionalIterator |
Constructors
Note: from this point onward, if a feature (eg. noexcept) is
specified which is only available in a particular language version,
that function is available for all language versions, but that aspect
of it is only available when that language version or higher is used.
Except where otherwise specified.
| standard |
constexpr colony() noexcept(noexcept(allocator_type))
explicit colony(const allocator_type &alloc) noexcept
explicit colony(plf::colony_limits minmax) noexcept(noexcept(allocator_type))
colony(plf::colony_limits minmax, const allocator_type &alloc) noexcept |
| copy |
colony(const colony &source)
colony(const colony &source, const std::type_identity_t<allocator_type> &alloc)
|
| move (C++11 and upwards) |
colony(colony &&source) noexcept
colony(colony &&source, std::type_identity_t<allocator_type> &alloc)
Note: postcondition state of source colony is the same as that of an empty colony.
|
| fill |
colony(size_type n, const allocator_type &alloc = allocator_type())
colony(size_type n, plf::colony_limits minmax, const allocator_type &alloc = allocator_type())
colony(size_type n, const value_type &element, const allocator_type &alloc = allocator_type())
colony(size_type n, const value_type &element, plf::colony_limits
minmax, const allocator_type &alloc = allocator_type()) |
| range |
template<typename InputIterator>
colony(const InputIterator &first, const InputIterator &last, const allocator_type &alloc = allocator_type())
template<typename InputIterator>
colony(const InputIterator &first, const InputIterator &last,
plf::colony_limits minmax, const allocator_type &alloc =
allocator_type())
|
| initializer list |
colony(const std::initializer_list<value_type> &element_list, const allocator_type &alloc = allocator_type())
colony(const std::initializer_list<value_type> &element_list,
plf::colony_limits minmax, const allocator_type &alloc =
allocator_type()) |
| ranges v3 (C++20 and upwards) |
template<class range_type>
requires std::ranges::range<range_type>
colony(plf::ranges::from_range_t, range_type &&rg, const allocator_type &alloc = allocator_type()):
template<class range_type>
requires std::ranges::range<range_type>
colony(plf::ranges::from_range_t, range_type &&rg, const
colony_limits block_limits, const allocator_type &alloc =
allocator_type()):
|
Some constructor usage examples
colony<T> a_colony
Default
constructor - default minimum group size is implementation-defined,
default maximum group size is std::numeric_limits<unsigned
short>::max() (unsigned char when priority::memory_use is used). You
cannot set the group sizes from the constructor in this scenario, but
you can call the reshape() member function after construction has
occurred.
Example: plf::colony<int>
int_colony;
colony<T, the_allocator<T> > a_colony(const
allocator_type &alloc = allocator_type())
Default constructor, but using a custom memory allocator e.g. something
other than std::allocator.
Example: plf::colony<int,
tbb::allocator<int> > int_colony;
Example2:
// Using an instance of an allocator as well as
it's type
tbb::allocator<int> alloc_instance;
plf::colony<int, tbb::allocator<int> >
int_colony(alloc_instance);
colony<T> colony(size_type n, plf::colony_limits minmax)
Fill constructor with value_type unspecified, so the value_type's
default constructor is used. n specifies the number of
elements to create upon construction. If n is larger than
minmax.min, the size of the groups created will either be
n and minmax.max, depending on which is
smaller. Setting the group sizes can be a performance
advantage if you know in advance roughly how many objects are likely to be
stored in your colony long-term - or at least the rough scale of storage.
If that case, using this can stop many small initial groups being
allocated (reserve() will achieve a similar result).
Example: plf::colony<int>
int_colony(62);
colony<T> colony(const std::initializer_list<value_type> &element_list)
Using an initialiser list to insert into the colony upon construction.
Example: std::initializer_list<int>
&el = {3, 5, 2, 1000};
plf::colony<int> int_colony(el, 64, 512);
colony<T> a_colony(const colony &source)
Copy all contents from source colony, removes any empty (erased) element
locations in the process. Size of groups created is either the total size
of the source colony, or the maximum group size of the source colony,
whichever is the smaller.
Example: plf::colony<int>
int_colony_2(int_colony_1);
colony<T> a_colony(colony &&source)
Move all contents from source colony, does not remove any erased element
locations or alter any of the source group sizes. Source colony is now empty and can be safely destructed or otherwise used.
Example: plf::colony<int> int_colony_1(50,
5, 512, 512); // Fill-construct a colony with min and max group sizes set at 512
elements. Fill with 50 instances of int = 5.
plf::colony<int> int_colony_2(std::move(int_colony_1)); // Move all
data to int_colony_2. All of the above characteristics are now applied to
int_colony2.
Iterators
All iterators are bidirectional but also provide >, <, >= and <=
for convenience (for example, in for loops). Functions for
iterator, reverse_iterator, const_iterator and const_reverse_iterator
follow:
operator *
operator ->
operator ++
operator --
operator =
operator ==
operator !=
operator <
operator >
operator <=
operator >=
operator <=> (C++20 and upwards)
base() (reverse_iterator and const_reverse_iterator only)
All operators have O(1) amortised time-complexity. Originally there were +=,
-=, + and - operators, however the time complexity of these varied from O(n) to
O(1) depending on the underlying state of the colony, averaging in at O(log n).
As such they were not includable in the iterator functions (as per C++
standards). These have been transplanted to colony's advance(), next(), prev()
and distance() member functions. Greater-than/lesser-than operator usage
indicates whether an iterator is higher/lower in position compared to another
iterator in the same colony (i.e. closer to the end/beginning of the colony).
const_iterator is provided for all C++ language versions.
Member functions
Insert
| single element |
iterator insert (value_type &val) |
| fill |
iterator insert (size_type n, value_type
&val) |
| range |
template <class InputIterator> iterator insert (InputIterator first, InputIterator last) |
| move (C++11 and upwards) |
iterator insert (value_type&& val) |
| initializer list |
iterator insert (std::initializer_list<value_type> il) |
| ranges v3 (C++20 and upwards) |
template<class range_type>
requires std::ranges::range<range_type>
void insert_range(range_type &&the_range) |
iterator insert(const value_type &element)
iterator insert(const_iterator hint, const value_type &element) C++20 and upwards
If a hint is supplied, it is ignored (included solely to support std::insert_iterator, it is an inactive parameter). Inserts the element supplied to the colony, using the object's
copy-constructor. Will insert the element into a previously erased element
slot if one exists, otherwise will insert to back of colony. Returns
iterator to location of inserted element. Example:
plf::colony<unsigned int> i_colony;
i_colony.insert(23); iterator insert(value_type &&element)
iterator insert(const_iterator hint, &&element) C++20 and upwards
If a hint is supplied, it is ignored. Moves the element supplied to the colony, using the object's
move-constructor. Will insert the element in a previously erased element
slot if one exists, otherwise will insert to back of colony. Returns
iterator to location of inserted element. Example:
std::string string1 = "Some text";
plf::colony<std::string> data_colony;
data_colony.insert(std::move(string1));
void insert (const size_type n, const value_type &val)
Inserts n copies of val into the colony. Will
insert the element into a previously erased element slot if one exists,
otherwise will insert to back of colony. Example:
plf::colony<unsigned int> i_colony;
i_colony.insert(10, 3); template <class InputIterator> void insert (const InputIterator &first, const InputIterator &last)
Inserts a series of value_type elements from an external
source into a colony holding the same value_type (e.g. int,
float, a particular class, etcetera). Stops inserting once it reaches
last. Example:
// Insert all contents of colony2 into
colony1:
colony1.insert(colony2.begin(), colony2.end()); void insert (const std::initializer_list<value_type>
&il)
Copies elements from an initializer list into the colony. Will insert the element in a previously erased element
slot if one exists, otherwise will insert to back of colony. Example:
std::initializer_list<int> some_ints =
{4, 3, 2, 5};
plf::colony<int> i_colony;
i_colony.insert(some_ints);
iterator emplace(Arguments &&...parameters) C++11 and
upwards
iterator emplace_hint(const_iterator hint, Arguments &&...parameters) C++20 and upwards
The hint in emplace_hint is ignored (included solely to support std::insert_iterator). Constructs new element directly within colony. Will insert the element
in a previously erased element slot if one exists, otherwise will insert to
back of colony. Returns iterator to location of inserted element.
"...parameters" are whatever parameters are required by the object's
constructor. Example:
class simple_class
{
private:
int number;
public:
simple_class(int a_number): number (a_number) {};
};
plf::colony<simple_class> simple_classes;
simple_classes.emplace(45);
Assign
| fill |
void assign (size_type n, value_type
&val) |
| range |
template <class InputIterator> void assign (InputIterator first, InputIterator last) |
| initializer list |
void assign (std::initializer_list<value_type> il) |
| ranges v3 (C++20 and upwards) |
template<class range_type>
requires std::ranges::range<range_type>
void assign_range(range_type &&the_range)
|
void assign (const size_type n, const value_type
&val)
Assigns n copies of val to the colony. Colony will erase all current contents and attempt to preserve existing memory blocks.
Example:
plf::colony<unsigned int> i_colony;
i_colony.assign(10, 3); template <class InputIterator> void assign (const InputIterator &first, const InputIterator &last)
Assigns a series of value_type elements from an external
source to the colony. Example:
// Assign all contents of colony2 into
colony1:
colony1.assign(colony2.begin(), colony2.end()); void assign (const std::initializer_list<value_type>
&il)
Assigns elements from an initializer list to the colony. Example:
std::initializer_list<int> some_ints =
{4, 3, 2, 5};
plf::colony<int> i_colony;
i_colony.assign(some_ints);
Erase
| single element |
iterator erase(const_iterator it) |
| range |
iterator erase(const_iterator first, const_iterator
last) |
iterator erase(const const_iterator it)
Removes the element pointed to by the supplied iterator, from the
colony. Returns an iterator pointing to the next non-erased element in the
colony (or to end() if no more elements are available). This must return an
iterator because if a colony group becomes entirely empty, it will be
removed from the colony, invalidating the existing iterator. Attempting to
erase a previously-erased element results in undefined behaviour (this is
checked for via an assert in debug mode). Example:
plf::colony<unsigned int>
data_colony(50);
plf::colony<unsigned int>::iterator an_iterator;
an_iterator = data_colony.insert(23);
an_iterator = data_colony.erase(an_iterator); iterator erase(const const_iterator first, const const_iterator last)
Erases all elements of a given colony from first to the
element before the last iterator. This function is optimized
for multiple consecutive erasures and will always be faster than sequential
single-element erase calls in that scenario. Example:
plf::colony<int> iterator1 =
colony1.begin();
colony1.advance(iterator1, 10);
plf::colony<int> iterator2 = colony1.begin();
colony1.advance(iterator2, 20);
colony1.erase(iterator1, iterator2);
Other functions
[[nodiscard]] bool empty() const noexcept
Returns a boolean indicating whether the colony is currently empty of
elements.
Example: if (object_colony.empty()) return;
size_type size() const noexcept
Returns total number of elements currently stored in container.
Example: std::cout << i_colony.size()
<< std::endl;
size_type max_size() const noexcept
Returns the maximum number of elements that the allocator can store in
the container.
Example: std::cout << i_colony.max_size()
<< std::endl;
size_type capacity() const noexcept
Returns total number of elements currently able to be stored in
container without expansion.
Example: std::cout << i_colony.capacity()
<< std::endl;
size_type memory() const noexcept
Returns
the memory use of the container plus it's elements. Does not include
memory dynamically-allocated by the elements themselves.
Example: std::cout << i_colony.memory()
<< std::endl;
void shrink_to_fit()
Reduces
container capacity to the amount necessary to store all currently
stored elements, consolidates elements and removes any erased
locations. If the total number of elements is larger than the maximum
group size, the resultant capacity will be equal to ((total_elements / max_group_size) + 1) * max_group_size
(rounding down at division). Invalidates all pointers, iterators and
references to elements within the container.
Example: i_colony.shrink_to_fit();
void trim_capacity() noexcept
void trim_capacity(size_type n) noexcept
Deallocates
any unused groups retained during erase() or unused since the last
reserve(). Unlike shrink_to_fit(), this function cannot invalidate
iterators or pointers to elements, nor will it shrink the capacity to
match size(). If n parameter is specified, will not remove a group if doing so will reduce the total capacity of the colony below n elements.
Example: i_colony.trim_capacity();
void reserve(const size_type reserve_amount)
Preallocates memory space sufficient to store the number of elements
indicated by reserve_amount.
This function is useful from a performance perspective when the user is
inserting elements singly, but the overall number of insertions is
known in advance. By reserving, colony can forgo creating many smaller
memory block allocations (due to colony's growth factor) and reserve
larger memory blocks instead.
Example: i_colony.reserve(15);
void clear() noexcept
Destroys
all elements and sets size() to zero. Currently existing groups are put
in the 'reserved groups' list for future use. To clear these groups as
well, follow up clear() with shrink_to_fit(), or just call reset()
instead (faster).
Example: object_colony.clear();
void reset() noexcept
Destroys
all elements, sets size() to zero, and deallocates all groups. Unlike
clear(), existing groups are not retained. Faster than clear() +
shrink_to_fit().
Example: object_colony.reset();
void reshape(plf::colony_limits minmax)
Changes
the minimum and maximum internal group sizes, in terms of number of
elements stored per group. If the colony is not empty and either
minmax.min is larger than the smallest group in the colony, or
minmax.max is smaller than the largest group in the colony, the colony
will be internally copy-constructed into a new colony which uses the
new group sizes, invalidating all pointers/iterators/references. If
trying to change group sizes with a colony storing a
non-copyable/movable type, an exception is thrown. If minmax.min or
minmax.max are outside of the colony's hard limits, an exception is
thrown.
Example: object_colony.reshape(plf::colony_limits(100, 1000));
constexpr plf::colony_limits block_capacity_limits() const noexcept
Returns the current minimum and maximum block limits within the .min and .max fields of a limits struct.
Example: plf::colony_limits temp = object_colony.block_capacity_limits();
static constexpr plf::colony_limits block_capacity_hard_limits() noexcept
Returns the current minimum and maximum hard
block limits within the .min and .max fields of a limits struct. In
this context 'hard' means, if the user supplies a block capacity limit
to a constructor or reshape(), which is above the hard maximum or below
the hard minimum, an exception is thrown. As a static member function,
this is designed to be able to be called before instatiating a colony
using user-defined limits, or before calling reshape().
static constexpr plf::colony_limits block_capacity_default_limits() noexcept
Returns the current minimum and maximum default block limits for a given colony type within the .min and .max fields of a limits struct.
static constexpr size_type block_capacity_default_min() noexcept
Returns the default minimum block limit for a given colony type.
static constexpr size_type block_capacity_default_max() noexcept
Returns the default maximum block limit for a given colony type.
void
swap(colony &source)
noexcept(std::allocator_traits<allocator_type>::propagate_on_container_swap::value
|| std::allocator_traits<allocator_type>::is_always_equal::value)
Swaps the colony's contents with that of source.
Example: object_colony.swap(other_colony);
void sort();
template <class comparison_function>
void sort(comparison_function compare);
Sort
the content of the colony. By default this compares the colony content
using a less-than operator, unless the user supplies a comparison
function (i.e. same conditions as std::list's sort function). Uses
std::sort internally but will use another sort function if it's name
(including namespace) is defined as the macro PLF_COLONY_SORT_FUNCTION
before including the colony .h. Supplied sort function must take same
parameters as std::sort.
Example: // Sort a colony of integers in ascending order:
int_colony.sort();
// Sort a colony of doubles in descending order:
double_colony.sort(std::greater<double>());
void unique()
template <class comparison_function>
void unique(comparison_function compare);
Removes
duplicates of values which are consecutive in the iterative sequence.
It is assumed that sort() will have been called before this function,
or that elements have been inserted in a specific order. By default
this compares the colony content using a == operator, unless the user
supplies a comparison function (i.e. same conditions as std::list's
unique function).
Example: // Remove duplicates in a colony of integers in ascending order:
int_colony.unique();
void splice(colony &source)
Transfer
all elements from source colony into destination colony without
invalidating pointers/iterators to either colony's elements (in other
words the destination takes ownership of the source's memory blocks).
After the splice, the source colony is empty. Splicing is much faster
than range-moving or copying all elements from one colony to another.
Colony does not guarantee a particular order of elements after
splicing, for performance reasons; the insertion location of source
elements in the destination colony is chosen based on the most positive
performance outcome for subsequent iterations/insertions. For example
if the destination colony is {1, 2, 3, 4} and the source colony is {5,
6, 7, 8} the destination colony post-splice could be {1, 2, 3, 4, 5, 6,
7, 8} or {5, 6, 7, 8, 1, 2, 3, 4}, depending on internal state of both
colonies and prior insertions/erasures.
Note: If the minimum
group size of the source is smaller than the destination, the
destination will change it's minimum group size to match the source.
The same applies for maximum group sizes (if source's is larger, the
destination will adjust its).
Example: // Splice two colonies of integers together:
colony<int> colony1 = {1, 2, 3, 4}, colony2 = {5, 6, 7, 8};
colony1.splice(colony2);
colony_data * data();
Returns a pointer to a dynamically-allocated struct with the following members:
colony::aligned_pointer_type * const block_pointers; // dynamically-allocated array of pointers to element memory blocks
unsigned char * * const bitfield_pointers; // dynamically-allocated
array of pointers to bitfields in the form of unsigned char arrays
// these represent whether an element is erased or not (0 for erased).
// they can be reinterpret_cast'd to whatever SIMD mask bitdepth is needed.
size_t * const block_capacities; // dynamically-allocated array of the number of elements in each memory block
const size_t number_of_blocks; // size of each of the arrays above
This
can be used with SIMD intrinsics to perform gather/scatter operations
on colony non-erased elements. Currently AVX512 is the only intel
instruction set with performance-efficient gather/scatter ops. The
structure must be freed with delete when finished with. See test suite
for a more thorough inspection of the structure.
Example:
colony<int> i_colony(10000, 5);
colony<int>::colony_data *data = i_colony.data();
// do stuff
delete data;
colony & operator = (const colony &source)
Copy the elements from another colony to this colony, clearing this
colony of existing elements first.
Example: // Manually swap data_colony1 and
data_colony2 in C++03
data_colony3 = data_colony1;
data_colony1 = data_colony2;
data_colony2 = data_colony3;
colony
& operator = (colony &&source)
noexcept(std::allocator_traits<allocator_type>::propagate_on_container_move_assignment::value
|| std::allocator_traits<allocator_type>::is_always_equal::value)C++11 and upwards
Move
the elements from another colony to this colony, clearing this colony
of existing elements first. Source colony is now empty and in a valid
state (same as a new colony without any insertions), can be safely
destructed or used in any regular way without problems.
Example: // Manually swap data_colony1 and
data_colony2 in C++11
data_colony3 = std::move(data_colony1);
data_colony1 = std::move(data_colony2);
data_colony2 = std::move(data_colony3);
colony & operator = (const std::initializer_list<value_type> il))
Copy the elements from an initializer list to this colony, clearing this
colony of existing elements first.
friend bool operator == (const colony &lh, const colony &rh) noexcept
Compare contents of one colony to this colony. Returns a boolean as
to whether their iterative sequences are equal.
Example: if (object_colony == object_colony2)
return;
friend bool operator != (const colony &lh, const colony &rh) noexcept
Compare contents of another colony to this colony. Returns a boolean as
to whether their iterative sequences are not equal.
Example: if (object_colony != object_colony2)
return;
iterator begin(), const_iterator begin(), iterator end(), const_iterator end(), const_iterator cbegin(),
const_iterator cend()
Return iterators pointing to, respectively, the first element of the
colony and the element one-past the end of the colony.
reverse_iterator rbegin(), const_reverse_iterator rbegin(), reverse_iterator rend(), const_reverse_iterator rend(),
const_reverse_iterator crbegin(), const_reverse_iterator crend()
Return reverse iterators pointing to, respectively, the last element of
the colony and the element one-before the first element of the colony.
iterator get_iterator(const_pointer element_pointer) noexcept
const_iterator get_const_iterator(const_pointer element_pointer) const noexcept
(non-O(1))
Getting a pointer from an iterator is simple - simply dereference it
then grab the address i.e. "&(*the_iterator);". Getting an
iterator from a pointer is typically not so simple. This function enables
the user to do exactly that. This is expected to be useful in the use-case
where external containers are storing pointers to colony elements instead
of iterators (as iterators for colonies have 3 times the size of an element
pointer) and the program wants to erase the element being pointed to or
possibly change the element being pointed to. Converting a pointer to an
iterator using this method and then erasing, is about 20% slower on average
than erasing when you already have the iterator.
This is less dramatic than it sounds, as it is still faster than all std:: container erasure times
which it is roughly equal to. However this is generally a slower,
lookup-based operation. If the lookup doesn't find a non-erased element
based on that pointer, it returns end().
Otherwise it returns an iterator pointing to the element in question.
For const pointers, use a const_cast when supplying the pointer to the
function, and for const_iterator, simply supply a const_iterator for
the return value. Example:
plf::colony<a_struct> data_colony;
plf::colony<a_struct>::iterator an_iterator;
a_struct struct_instance;
an_iterator = data_colony.insert(struct_instance);
a_struct *struct_pointer = &(*an_iterator);
iterator another_iterator =
data_colony.get_iterator(struct_pointer);
if (an_iterator == another_iterator) std::cout << "Iterator is
correct" << std::endl;
bool is_active(const const_iterator it) const
This is similar to get_iterator(pointer), but for iterators. For a
given iterator, returns whether or not the location the iterator points
to is still valid ie. that it points to an active non-erased element in
a memory block which is still allocated. It does not differentiate
between memory blocks which have been re-used - the only thing it
reports, is whether the memory block pointed to by the iterator exists
in an active state in this particular colony, and if there is an
element being pointed to by the iterator, in that memory block, which
is also in an active, non-erased state.
static constexpr size_type block_metadata_memory(const size_type block_capacity) noexcept
Given
a block element capacity, tells you, for this particular colony type,
what the resultant amount of metadata (including skipfield) allocated
for that block will be, in bytes.
static constexpr size_type block_allocation_amount(const size_type block_capacity) noexcept
Given
a block element capacity, tells you, for this particular colony type,
what the resultant allocation for that block will be, in bytes. In
terms of this version of colony, the block and skipfield are allocated
at the same time (other block metadata is allocated separately). So
this function is expected to be primarily useful for developers working
in environments where an allocator or system only allocates a specific
capacity of memory per call, eg. some embedded platforms.
static constexpr size_type max_elements_per_allocation(const size_type allocation_amount) noexcept
Given
a fixed allocation amount, tells you, for this particular colony type,
exactly what the maximum element capacity per-block can be. In other
words, if an allocator can only supply a fixed or low amount of memory
per allocation, this function tells the developer the upper limit of
what their max block capacity limit should be set to in the constructor
(or in reshape()). Like the above this function is expected to be
primarily useful for developers working in embedded environments. The
return value is bounded by the colony's maximum hard block capacity
limit (255 or 65535 depending on the type and priority_type used) and
will return zero if the return value is below the colony's minimum hard
block capacity limit (currently 3).
Non-member function overloads
template <class iterator_type> void advance(iterator_type iterator,
const distance_type distance)
Increments/decrements the iterator supplied by the positive or negative
amount indicated by distance. Speed of incrementation will almost
always be faster than using the ++ operator on the iterator for increments
greater than 1. In some cases it may approximate O(1). The iterator_type
can be an iterator, const_iterator, reverse_iterator or
const_reverse_iterator.
Example: colony<int>::iterator it =
i_colony.begin();
i_colony.advance(it, 20);
template <class iterator_type> iterator_type next(iterator_type &iterator, const distance_type distance)
Creates a copy of the iterator supplied, then increments/decrements this
iterator by the positive or negative amount indicated by
distance.
Example: colony<int>::iterator it =
i_colony.next(i_colony.begin(), 20);
template <class iterator_type> iterator_type prev(iterator_type &iterator, const distance_type distance)
Creates a copy of the iterator supplied, then decrements/increments this
iterator by the positive or negative amount indicated by
distance.
Example: colony<int>::iterator it2 =
i_colony.prev(i_colony.end(), 20);
template <class iterator_type> difference_type distance(const iterator_type &first, const iterator_type &last)
Measures the distance between two iterators, returning the result, which
will be negative if the second iterator supplied is before the first
iterator supplied in terms of it's location in the colony.
Example: colony<int>::iterator it =
i_colony.next(i_colony.begin(), 20);
colony<int>::iterator it2 = i_colony.prev(i_colony.end(), 20);
std::cout "Distance: " i_colony.distance(it, it2) std::endl;
template <class container_type> void std::swap(container_type &A, container_type &B)
Swaps colony A's contents with that of colony B (assumes both colonies
have same element type, allocator type, etc).
Example: swap(object_colony, other_colony);
template <class container_type, class predicate> size_type std::erase_if(container_type A, predicate pred)
Erases all elements in the colony which match predicate pred. Returns the number of erased elements.
template <class container_type> size_type std::erase(container_type A, container_type::value_type v)
Erases all elements in the colony which == v. Returns the number of erased elements.
template <plf::colony_iterator_concept it_type>
class reverse_iterator<it_type> : public it_type::reverse_type
Overload
for std::reverse_iterator, for returning a reverse_iterator from a
supplied colony iterator/const_iterator. Primarily intended for use
with ranges v3.
Benchmarks
Benchmark results for colony v6.11 under GCC 9.2 x64 on an Intel Xeon E3-1241 (Haswell) are here.
Old benchmark results for colony v3.87 under GCC 5.1 x64 on an Intel E8500 (Core2) are here,
and under MSVC 2015 update 3 on an Intel Xeon E3-1241 (Haswell) are here. There is no commentary for the MSVC results.
Benchmark results for plf::hive (mostly same as plf::colony internally) vs boost::huv are here.
Frequently Asked Questions
TLDR, what is a colony?
A combination of a linked-list of increasingly-large memory blocks with metadata. Part of
this metadata is the head of a free-list of erased elements within that
group, and also a 'next' pointer to the next group which has erased
element locations which can be re-used. Another part of the metadata is
a low complexity jump-counting skipfield, which is used to skip over
erased elements during iteration in O(1) amortised time. The end
result's a bidirectional, unordered C++ template data container which
maintains positive performance characteristics while ensuring pointer
stability to non-erased container elements.
Where is it worth using a colony in place of other std::
containers?
As mentioned, it is worthwhile for performance reasons in situations
where the order of container elements is not important and:
- Insertion order is unimportant
- Insertions and erasures to the container occur frequently in
performance-critical code, and
- Links to non-erased container elements may not be invalidated by
insertion or erasure.
Under these circumstances a colony will generally out-perform other
std:: containers. In addition, because it never invalidates pointer
references to container elements (except when the element being pointed to
has been previously erased) it may make many programming tasks involving
inter-relating structures in an object-oriented or modular environment much
faster, and could be considered in those circumstances.
What are some examples of situations where a colony might improve
performance?
Some ideal situations to use a colony: cellular/atomic simulation,
persistent octtrees/quadtrees, game entities or destructible-objects in a
video game, particle physics, anywhere where objects are being created and
destroyed continuously. Also, anywhere where a vector of pointers to
dynamically-allocated objects or a std::list would typically end up being
used in order to preserve object references but where order is
unimportant.
What are the time complexities for general operations?
In
most cases the time complexity of operations results from the
fundamental requirements of the container itself, not the
implementation. In some cases, such as erase complexity, this can
change a little based on the implementation, but the change is minor.
Insert (single): O(1) amortised
One
of the requirements of colony is that pointers to non-erased elements
stay valid regardless of insertion/erasure within the container. For
this reason the container must use multiple memory blocks. If a single
memory block were used, like in a std::vector, reallocation of elements
would occur when the container expanded (and the elements were copied
to a larger memory block). Hence, colony will insert into existing
memory blocks when able, and create a new memory block when all
existing memory blocks are full.
Because colony (by default)
has a growth pattern for new memory blocks, the number of insertions
before a new memory block is required increases as more insertions take
place. Hence the insertion time complexity is O(1) amortised.
Insert (multiple): O(N) amortised
This
follows the same principle - there will occasionally be a need to
create a new memory block, but since this is infrequent it is O(N)
amortised.
Erase (single): O(1) amortised (as of v5.00)
Generally
speaking erasure is a simple matter of destructing the element in
question and updating the skipfield. Since we started using the low
complexity jump-counting pattern (v5.00) instead of the high complexity
jump-counting skipfield pattern, that skipfield update is always O(1).
However, when a memory block becomes empty of non-erased elements it
must be freed to the OS (or stored for future insertions, depending on
implementation) and removed from the colony's sequence of memory
blocks. It it was not, we would end up with non-O(1) amortised
iteration, since there would be no way to predict how many empty memory
blocks there would be between the current memory block being iterated
over, and the next memory block with non-erased (active) elements in
it. Since removal of memory blocks is infrequent the time complexity
becomes O(1) amortised.
Erase (multiple): O(N) amortised
for non-trivially-destructible types, for trivially-destructible types
between O(1) and O(N) amortised depending on range start/end
(approximating O(log n) average)
In this case, where the
element is non-trivially destructible, the time complexity is O(N)
amortised, with infrequent deallocation necessary from the removal of
an empty memory block as noted above. However where the elements are
trivially-destructible, if the range spans an entire memory block at
any point, that block and it's skipfield can simply be removed without
doing any individual writes to it's skipfield or individual destruction
of elements, potentially making this a O(1) operation.
In
addition (when dealing with trivially-destructible types) for those
memory blocks where only a portion of elements are erased by the range,
if no prior erasures have occurred in that memory block you can erase
that range in O(1) time, as there will be no need to check within the
range for previously erased elements, and the low complexity
jump-counting pattern only requires two skipfield writes to indicate a
range of skipped nodes. The reason you would need to check for
previously erased elements within that portion's range is so you can
update the metadata for that memory block to accurately reflect how
many non-erased elements remain within the block. If that metadata is
not present, there is no way to ascertain when a memory block is empty
of non-erased elements and hence needs to be removed from the colony.
The reasoning for why empty memory blocks must be removed is included
in the Erase(single) section, above.
However in most cases the
erase range will not perfectly match the size of all memory blocks, and
with typical usage of a colony there is usually some prior erasures in
most memory blocks. So for example when dealing with a colony of a
trivially-destructible type, you might end up with a tail portion of
the first memory block in the erasure range being erased in O(N) time,
the second and intermediary memory block being completely erased and
freed in O(1) time, and only a small front portion of the third and
final memory block in the range being erased in O(N) time. Hence the
time complexity for trivially-destructible elements approximates O(log
n) on average, being between O(1) and O(N) depending on the start and
end of the erasure range.
std::find: O(n)
This relies on basic iteration so is O(N).
splice: O(1)
Colony
only does full-container splicing, not partial-container splicing (use
range-insert with std::move to achieve the latter, albiet with the loss
of pointer validity to the moved range). When splicing the memory
blocks from the source colony are transferred to the destination colony
without processing the individual elements or skipfields, inserted
after the destination's final block. However if there are unused
element memory spaces at the back of the destination container (ie. the
final memory block is not full), the skipfield nodes corresponding to
those empty spaces must be altered to indicate that these are skipped
elements. Luckily as of v5.00 this is also a O(1) operation, hence the
overall operation is O(1).
Iterator operators ++ and --: O(1) amortised
Generally the time complexity is O(1), as the skipfield pattern used (current)
must allow for skipping of multiple erased elements. However every so
often iteration will involve a transistion to the next/previous memory
block in the colony's sequence of blocks, depending on whether we are
doing ++ or --. At this point a read of the next/previous memory
block's corresponding skipfield is necessary, in case the first/last
element(s) in that memory block are erased and hence skipped. So for
every block transition, 2 reads of the skipfield are necessary instead
of 1. Hence the time complexity is O(1) amortised.
Skipfields
must be per-block and independent between memory blocks, as otherwise
you would end up with a vector for a skipfield, which would need a
range erased every time a memory block was removed from the colony (see
notes under Erase above), and reallocation to larger skipfield memory
block when the colony expanded. Both of these procedures carry
reallocation costs, meaning you could have thousands of skipfield nodes
needing to be reallocated based on a single erasure (from within a
memory block which only had one non-erased element left and hence would
need to be removed from the colony). This is unacceptable latency for
any fields involving high timing sensitivity (all of SG14).
begin()/end(): O(1)
For any implementation these should generally be stored as member variables and so returning them is O(1).
advance/next/prev: between O(1) and O(n), depending on current iterator location and distance. Average approximates O(log N).
The
reasoning for this is similar to that of Erase(multiple), above. Memory
blocks which are completely traversed by the increment/decrement
distance can be skipped in O(1) time by reading the metadata for the
block which details the number of non-erased elements in the block. If
the current iterator location is not at the very beginning of a memory
block, then the distance within that block will need to be processed in
O(N) time, unless no erasures have occurred within that block, in which
case the skipfield does not need to be checked and traversal is simply
a matter of pointer arithmetic and checking the distance between the
current iterator position and the end of the memory block, which is a
O(1) operation.
Similarly for the final block involved in the
traversal (if the traversal spans multiple memory blocks!) if no
erasures have occurred in that memory block pointer arithmetic can be
used and the procedure is O(1), otherwise it is O(N) (++ iterating over
the skipfield). We can therefore say that the overall time complexity
for these operations might approximate O(log N), while being between
O(1) and O(N) amortised respectively.
Is it similar to a deque?
A deque is
reasonably dissimilar to a colony - being a double-ended queue, it
requires a different internal framework. It typically uses a vector of
memory blocks, whereas the colony implementation uses a linked list of
memory blocks, essentially. A deque can't technically use a linked list
of memory blocks because it will make some random_access iterator
operations (e.g. + operator) non-O(1). In addition, being random-access
container, having a growth factor for memory blocks in a deque is
problematic (not impossible though).
A deque and colony have no comparable performance characteristics except
for insertion (assuming a good deque implementation). Deque erasure
performance varies wildly depending on the implementation compared to
std::vector, but is generally similar to vector erasure performance. A
deque invalidates pointers to subsequent container elements when erasing
elements, which a colony does not.
What are the thread-safe guarantees?
Unlike a std::vector, a colony can be read from and inserted into at the
same time (assuming different locations for read and write), however it
cannot be iterated over and written to at the same time. If we look at a
(non-concurrent implementation of) std::vector's thread-safe matrix to see
which basic operations can occur at the same time, it reads as follows
(please note push_back() is the same as insertion in this regard):
| std::vector |
Insertion |
Erasure |
Iteration |
Read |
| Insertion |
No |
No |
No |
No |
| Erasure |
No |
No |
No |
No |
| Iteration |
No |
No |
Yes |
Yes |
| Read |
No |
No |
Yes |
Yes |
In other words, multiple reads and iterations over iterators can happen
simultaneously, but the potential reallocation and pointer/iterator
invalidation caused by insertion/push_back and erasure means those
operations cannot occur at the same time as anything else.
Colony on the other hand does not invalidate pointers/iterators to
non-erased elements during insertion and erasure, resulting in the
following matrix:
| plf::colony |
Insertion |
Erasure |
Iteration |
Read |
| Insertion |
No |
No |
No |
Yes |
| Erasure |
No |
No |
No |
Mostly* |
| Iteration |
No |
No |
Yes |
Yes |
| Read |
Yes |
Mostly* |
Yes |
Yes |
* Erasures will not invalidate iterators
unless the iterator points to the erased element.
In other words, reads may occur at the same time as insertions and
erasures (provided that the element being erased is not the element being
read), multiple reads and iterations may occur at the same time, but
iterations may not occur at the same time as an erasure or insertion, as
either of these may change the state of the skipfield which's being
iterated over. Note that iterators pointing to end() may be invalidated by
insertion.
So, colony could be considered more inherently thread-safe than a
(non-concurrent implementation of) std::vector, but still has some areas
which would require mutexes or atomics to navigate in a multithreaded
environment.
Any pitfalls to watch out for?
- Because erased-element memory locations will be reused by
insert() and emplace(), insertion position is
essentially random unless no erasures have been made, or an equal
number of erasures and insertions have been made.
- Due
to implementation reasons it is possible to assign (or construct) a
iterator from a const_iterator, which is not really good const
behaviour (only assigning/constructing a const_iterator from an
iterator is good const practice). However preventing this results in
errors in all versions of MSVC, so it has been ignored.
Am I better off storing iterators or pointers to colony elements?
Testing so far indicates that storing pointers and then using
get_iterator() when or if you need to do an erase
operation on the element being pointed to, yields better performance than
storing iterators and performing erase directly on the iterator. This is
simply due to the size of iterators (3 pointers in width).
Any special-case uses?
In the special case where many, many elements are being continually
erased/inserted in realtime, you might want to experiment with limiting the
size of your internal memory groups in the constructor. The form of this is
as follows:
plf::colony<object> a_colony(plf::colony_limits(500, 5000));
where the first number is the minimum size of the internal memory groups
and the second is the maximum size. Note these can be the same size,
resulting in an unchanging group size for the lifetime of the colony
(unless reshape is called or operator = is
called).
One
reason to do this is that it is slightly slower to obtain an element
location from the list of groups-with-erasures (subsequently utilising
that group's free list of erased locations), than it is to insert a new
element to the end of the colony (the default behaviour when there are
no previously-erased elements). If there are any erased elements in the
colony, the colony will recycle those memory locations, unless the
entire group is empty, at which point it is freed to memory. So if a
group size is large and many, many erasures occur but the group is not
completely emptied, iterative performance may suffer due to large
memory gaps between any two non-erased elements. In that scenario you
may want to experiment with benchmarking and limiting the
minimum/maximum sizes of the groups, and find the optimal size for a
particular use case.
Please note that the the fill, range and initializer-list constructors
can also take group size parameters, making it possible to construct filled
colonies using custom group sizes.
What is colony's Abstract Data Type (ADT)?
Though I am happy to be proven wrong I suspect colony is it's own
abstract data type. While it is similar to a multiset or bag, those utilize
key values and are not sortable (by means other than automatically by key
value). Colony does not utilize key values, is sortable, and does not
provide the sort of functionality one would find in a bag (e.g. counting the
number of times a specific value occurs). Some have suggested similarities
to deque - but as described earlier the three core aspects of colony
are:
- A multiple-memory-block based allocation pattern which allows for the
removal of memory blocks when they become empty of elements.
- A skipfield to indicate erasures instead of reallocating elements,
the iteration of which should typically not necessitate the use of
branching code.
- A mechanism for recording erased element locations to allow for reuse
of erased element memory space upon subsequent insertion.
The only aspect out of these which deque also shares is a
multiple-memory-block allocation pattern - not a strong association. As a
result, deques do not guarantee pointer validity to non-erased elements
post insertion or erasure, as colony does. Similarly if we look at a
multiset, an unordered one could be implemented on top of a colony by
utilising a hash table (and would in fact be more efficient than most
non-flat implementations) but the fact that there is a necessity to add
something to make it a multiset (to take and store key values) means colony
is not an multiset.
Exception Guarantees?
All operations which allocate memory have strong exception guarantees
and will roll back if an exception occurs, except for operator = which has
a basic exception guarantee (see below). For colony, iterators are bounded
by asserts in debug mode, but unbounded in release mode, so it is possible
for an incorrect use of an iterator (iterating past end(), for example) to
trigger an out-of-bounds memory exception.
The reason why operator = only has a basic guarantee is they do not
utilize the copy-swap idiom, as the copy-swap idiom significantly increases
the chance of any exception occurring - this is because the most common way
an exception tends to occur during a copy operation is due to a lack of
memory space, and the copy-swap idiom doubles the memory requirement for a
copy operation by constructing the copy before destructing the original
data.
This is doubly inappropriate in game development, which colony has
been initially for, where memory constraints are often critical and the
runtime lag from memory spikes can cause detrimental game performance. So
in the case of colony if a non-memory-allocation-based exception occurs
during copy, the = operators will have already destructed their data, so
the containers will be empty and cannot roll back - hence they have a basic
guarantee, not a strong guarantee.
Iterators not following rule of zero?
It was found under GCC and clang that the high-modification scenario
benchmarks suffered a 11% overall performance loss when iterator copy and
move constructors/operators where not explicitly defined, possibly because
GCC did not know to vectorize the operations without explicit code or
because the compiler implemented copy/swap idiom instead of simply copying
directly. No performance gain was found under any tests when removing the
copy and move constructors/operators.
Why must groups be removed when
empty?
Two reasons:
- Standards compliance: if groups aren't removed then
++
and -- iterator operations become O(random) in terms of
time complexity, making them non-compliant with the C++ standard. At
the moment they are O(1) amortised, typically one update for both
skipfield and element pointers, but two if a skipfield jump takes the
iterator beyond the bounds of the current group and into the next
group. But if empty groups are allowed, there could be anywhere between
1 and size_type
empty groups between the current element and the next. Essentially you
get the same scenario as you do when iterating over a boolean
skipfield. It would be possible to move these to the back of the colony
as trailing groups, but this may create performance issues if any of
the groups are not at their maximum size (see below).
- Performance:
iterating over empty groups is slower than them not being present,
cache wise - but also if you have to allow for empty groups while
iterating, then you have to include a while loop in every iteration
operation, which increases cache misses and code size. The strategy of
removing groups when they become empty also removes (assuming
randomised erasure patterns) smaller groups from the colony before
larger groups, which has a net result of improving iteration, because
with a larger group, more iterations within the group can occur before
the end-of-group condition is reached and a jump to the next group (and
subsequent cache miss) occurs. Lastly, pushing to the back of a colony
is faster than recycling memory locations as each insertion occurs in
subsequent similar memory location (which is cache-friendlier) and also
less computational work is necessary. If a group is removed it's
recyclable memory locations are also removed from re-use, hence
subsequent insertions are more likely to be pushed to the back of the
colony.
Why use three pointers for iterators rather than a group pointer,
single index and then dereferencing?
It's faster. In attempting on two separate occasions to switch to an
index-based iterator approach, utilising three separate pointers was
consistently faster.
Group sizes - what are they based on, how do they expand, etc
Group sizes start from the either the
default minimum size (8 elements, larger if the type stored is small) or an
amount defined by the programmer (with a minimum of 3 elements). Subsequent
group sizes then increase the total capacity of the colony by a
factor of 2 (so, 1st group 8 elements, 2nd 8 elements, 3rd 16 elements, 4th
32 elements etcetera) until the maximum group size is reached. The default
maximum group size is the maximum possible number that the skipfield
bitdepth is capable of representing
(std::numeric_limits<skipfield_type>::max()). By default the
skipfield bitdepth is 16 so the maximum size of a group is 65535 elements.
However the skipfield bitdepth is also a template parameter which can be
set to any unsigned integer - unsigned char, unsigned int, Uint_64, etc.
Unsigned short (guaranteed to be at least 16 bit, equivalent to C++11's
uint_least16_t type) was found to have the best performance in real-world
testing due to the balance between memory contiguousness, memory waste and
the restriction on skipfield update time complexity. Initially the design
also fitted the use-case of gaming better (as games tend to utilize lower
numbers of elements than some other fields), and that was the primary
development field at the time.
Why store a size member for each group when this can be obtained via
reinterpret_cast<element_pointer_type>(skipfield) -
elements?
Because
it's faster. While it can be obtained that way, having it precalculated
gives a small but significant benefit. And it's only an additional 16
bits per group under 32-bit code (under 64-bit code there is typically
no additional size increase, due to struct padding and the size of
pointers).
Can a colony be used with SIMD instructions?
No and yes. Yes if you're careful, no if you're not.
On platforms which support scatter and gather operations you can use
colony with SIMD as much as you want, using gather to load elements
from disparate or sequential locations, into a SIMD register. Then use
scatter to push the post-SIMD-process values elsewhere after. The
data() function is useful for this.
On platforms which require elements to be contiguous in memory for SIMD
processing, this is more complicated. When you have a bunch of erasures
in a colony, there's no guarantee that your objects will be contiguous
in memory, even though they are sequential during iteration. Some of
them may also be in different memory blocks to each other. In these
situations if you want to use SIMD with colony, you must do the
following:
- Set
your minimum and maximum group sizes to multiples of the width of your
SIMD instruction. If it supports 8 elements at once, set the group
sizes to multiples of 8.
- Either never erase from the colony, or:
- Shrink-to-fit after you erase (will invalidate all pointers to elements within the colony).
- Only
erase from the back or front of the colony, and only erase elements in
multiples of the width of your SIMD instruction e.g. 8 consecutive
elements at once. This will ensure that the end-of-memory-block
boundaries line up with the width of the SIMD instruction, provided
you've set your min/max block sizes as above.
Generally if you want to use SIMD without gather/scatter, it's probably preferable to use a vector or an array.
Version history
- 2026-07-08: v7.6.82 - avoid unused variable warnings. Removed workaround for old bug in MSVC as is now fixed (incorrect warning at warning level 4 when non-constant expressions were used in non-constexpr-if blocks, and MSVC thought they should be if-constexpr). Correction to type trait semantics in sort(). Compiler feature macro definitions and common tools moved out into plf_tools.h (shared amongst plf:: projects). Corrections to plf::uninitialized_copy and plf::uninitialized_move. Minor corrections.
- 2026-06-28: v7.6.70 - Fix for advance/next/prev when reverse_iterators used and rbegin() might be reached + performance increase for all 3. Correction to function definition of prev. Added safety-check for get_iterator in circumstances where a block of memory which got deallocated by the container, then another block got allocated by the container which contained that memory space, but the new block is not exactly aligned with the old block. eg. colony<structure> where structure = struct {int x, y} and the new memory block is offset by 1 int such that 'element_pointer' points at y.
- 2026-05-25: v7.6.54 - Today I learned: decrementing a pointer to before the beginning of an array in C++ is UB even if the value is never accessed, unlike incrementing 1 past the end of an array.
reverse_iterator style was inadvertently invoking UB by decrementing before begin() to represent rend() in my style of reverse_iterator. This was overall a faster style, as it involved fewer operations during use but unfortunately, UB. Fixed, and a side effect of this is that iterator::operator-- can be reduced as well. Minor optimisation for iterator::operator++ under MSVC in certain benchmarks. Correction to exception type for checking user-defined block capacity limits. Correction to reverse_iterator + erase test in test suite.
Corrections to C++11/14/MSVC2010 support.
- 2026-05-22: v7.6.50 - Breaking change: reverse_iterator::advance no longer bounds to rend(), and iterator::operator-- no longer bounds to begin(). This allows for reverse_iterator to use iterator's advance() and operator-- instead of defining it's own. Still using custom reverse_iterator instead of std::reverse_iterator>iterator< because the latter doesn't result in a trivially-copyable reverse_iterator and also has more codegen. This results in significant code reduction and repeatable 3% speed increase when benchmarking the test suite. Better allocator conformance - uninitialized_fill/copy functions replaced with construct loops when the allocator has a custom-defined construct function, uses uninitialized_fill/copy internally when it doesn't (to take advantage of the optimized routines for POD types in those functions. Some code reduction. Native visualisation (natvis) support added for MSVC, courtesy of Pavlo Ilan.
- 2026-05-14: v7.6.13 - Correction to exception recovery during fill/range/initializer_list/rangesv3 insertion when there is a skipblock present in the hive. Additional tests added in this area.
- 2026-05-13: v7.6.12 - Fixes to nothrow tests on emplace(). Correction to ranges support to disallow ranges of non-value_types and/or ranges of output-only iterators. Thanks to Slaven for pointing these out. Added tests to test suite to check functionality after exception thrown during fill-insertion.
- 2026-03-03: v7.6.10 - Iterators are now trivially-copyable - this can make performance better for some external iterator-based algorithms. Many functions which take iterators have been switched to references, as colony iterators are largeish and this improves performance. Up to 9% faster average insertion in single-function micro-benchmarks, depending on CPU. Correction: added some missing skipfield conversions for if an allocator supplies non-trivial pointers. Added additional comments on skipfield implementation, since I've had multiple people make some incorrect assumptions. Minor code reduction.
- 2026-01-02: v7.6.03 - Correction to allocator-supplied move constructor when allocators are not equal. Remove some MSVC warnings.
- 2025-12-23: v7.6.01 - Correction for range erase. Some older versions of clang complained about some basic legitimate uses of +=/-= with non-size_type's. Newer versions don't seem to be making the same bad warnings, so removed some of the workarounds.
- 2025-12-22: v7.6.00 - Major code reduction/simplification for range erase. Added more extensive comments explaining range erase logic. Clarified other comments. Some other minor optimisations/code reductions.
- 2025-12-01: v7.5.88 - Revert prev optimisation as it conflicts with allocators whose default constructors aren't constexpr, like PMR ones.
- 2025-12-01: v7.5.87 - Minor optimisation for block_capacity_default_min.
- 2025-11-27: v7.5.86 - fix for conversion warnings.
- 2025-11-22: v7.5.85 - range-based assign() operations and operator= (&t) now both correctly preserve the order of the range in colonies of non-trivial types. Performance improvement for both operations.
- 2025-11-06: v7.5.71 - Noexcept removal for colony(const plf::limits block_limits, const allocator_type &alloc) constructor (may throw if block limits are outside of block_capacity_hard_limits).
- 2025-11-02: v7.5.70 - Corrections for when the allocator supplied to the container returns smart pointers. Previously multiple areas would not work due to the need for pointer arithmetic, and if the allocator returned, for example, a unique_ptr, the supplied memory would've been deallocated prematurely. This is also fixed in sort(), where a mismatch of pointer types might've caused problems. Minor optimisation for pointer_cast in debug mode when both pointer types are raw.
- 2025-10-29: v7.5.62 - Minor reordering in allocate_new_group to create fewer issues if exception is triggered by first allocation (Thanks to Slaven for pointing this out).
- 2025-10-28: v7.5.61 - Fix potential overflow in max_size() comparisons if type is byte-sized.
- 2025-10-27: v7.5.60 - Correction and optimization to reserve(). Also if reserve deallocates a reserved block, it now does so after a new block has been allocated - to avoid the container ending up with less capacity() than when it started, should an exception occur during allocation of the new block. New block allocations now check to see if they're taking the container capacity over max_size(). Minor optimizations. Code reductions.
- 2025-09-26: v7.5.41 - Correction to reserve(). Removal of unnecessary group number check in reserve + minor optimisation.
- 2025-09-25: v7.5.40 - Optimization to reserve() - will now attempt to consolidate some of the requested additional capacity with pre-existing small reserved blocks, making for larger block capacities overall, better cache locality.
- 2025-09-22: v7.5.37 - Resolve conversion warnings under MSVC for reserve().
- 2025-09-16: v7.5.36 - reserve() now throws when n <= max_size() but block capacity limits mean that a resultant capacity() <= n would be by necessity > max_size(). Thanks to Bloomberg for pointing this out. reserve() algorithm improved and is now more accurate in terms of resultant capacity(). eg. when block capacity limits min = 50 and max = 70, and reserve(150) is called, resultant capacity will be 150 instead of (previously) 190. Another minor exception correction (unnecessary deallocation call) in reserve(). Correction to copy/ranges/initializer_list constructor, range/ranges/initializer_list insert/assign and operator =, when type isn't copy-constructible but is move-constructible (this is also a correction for C++03 support).
- 2025-07-11: v7.5.26 - Correction to type traits as C++26 deprecates std::is_trivial.
- 2025-05-20: v7.5.25 - Fix for when an allocator doesn't supply a constexpr default constructor under C++23 eg. std::pmr::polymorphic_allocator.
- 2025-03-06: v7.5.23 - Adjustment to assign behaviour when type has non-trivial assignment, just in case there is some odd assignment behaviour in otherwise trivial types.
- 2025-03-04: v7.5.22 - Minor adjustment to assign behaviour when type traits aren't available.
- 2025-03-03: v7.5.21 - Corrections/optimizations to all assign functions where type is non-trivial, and to operator = &&. Optimizations to copy/move/fill/initializer_list/range/rangesv3 constructors, fill/range/initializer_list/rangesv3 insert, reshape, shrink_to_fit.
- 2025-02-28: v7.5.10 - Fix for move assignment and splice when type has deleted move and/or copy constructor. Also minor optimization for move assignment/splice under C++20 and above. Correction to C++03 support. Correction to operator =.
- 2025-02-09: v7.5.6 - Technical correction to copy construction under MSVC.
- 2024-12-14: v7.5.5 - Corrections to move constructor, copy assignment, move assignment, fill insert/assign/construct. Minor performance improvement to copy assignment under C++20 and above.
- 2024-12-03: v7.5.3 - Added hint-supporting versions of insert, and emplace_hint (the hint is ignored in both cases) to support std::insert_iterator().
- 2024-11-04: v7.5.2 - Corrections to const use on move assignment/construction in iterators.
- 2024-10-30: v7.5.1 - Optimization for erase(begin, end) when there are no erasures in a block and the element type is non-trivially-destructible (or type traits are unavailable).
- 2024-10-19: v7.5.0 - Corrected block_limits functions so that they take into account the max_size() provided by the allocator. Made all default constructors constexpr.
default_block_capacity_limits(), default_min_block_capacity() and default_max_block_capacity() changed to block_capacity_default_limits(), block_capacity_default_min() and block_capacity_default_max() (to match hive and be consistent with naming of block_capacity_hard_limits()).
- 2024-10-14: v7.4.8 - West const 4 lyfe - there was inconsistent use of const throughout due to my misunderstanding of how typedefs change const expession in C++. Added [[unlikely]] to a couple of places which will only trigger once in U32::max() group allocations.
- 2024-09-07: v7.4.7 - minor optimisation to get_iterator()/is_active() + bugfix for when they're used on a colony with no blocks. Update to test suite.
- 2024-09-04: v7.4.6 - correction to get_iterator() and is_active() when pointer/iterator do not point to elements currently existing in the colony instance. Thanks to Mishura4 for spotting the bug.
- 2024-07-17: v7.4.4 - Fix to support under GCC5 with -std=c++11, courtesy of Martin Valgur.
- 2024-04-21: v7.4.3 - Minor optimisations to iterator operator -- and reverse_iterator operator ++. Minor code reduction.
- 2024-04-10: v7.4.2 - Change to vcpkg-compatible versioning. plf::make_move_iterator changed to be static. plf::equal_to uses references now and is entirely noexcept.
- 2024-01-03: v7.41 - Macro code reduction.
- 2023-12-26: v7.40 - Minor optimisation for shrink_to_fit()/reshape(). Correction & optimisation to unique(). Optimisation to erase_if()/erase() overloads.
- 2023-12-09: v7.39 - Fix for insert + building with/without exceptions.
- 2023-12-06: v7.38 - Bugfix for reserved blocks not being correctly added back into source in splice(). Replaced some ternary instances with std::min/max for clarity. Correction to erase() assert. Needless comment removal.
- 2023-12-04: v7.37 - sort optimisation with memory, minor optimisation to unique() and std::erase_if overloads, semantic correction to get_allocator.
- 2023-11-30: v7.36 - Fix bug where if splice was used and someone tried inserting into the empty source hive post-splice it could've caused an issue.
- 2023-11-25: v7.35 - Optimisation to reshape(). Removed code in reshape to check for non-copyable/movable status of type as program will not compile with the type in question if reshape may be called (and copying/moving is thereby mandated). Minor optimisation to splice() block checking. Correction to splice() when order of source/destination blocks swapped. Swapped some manual swapping with std::swap where appropriate.
- 2023-11-14: v7.34 - Correction to splice() when destination is empty (no longer transfers allocator or block limits).
- 2023-10-12: v7.33 - shrink_to_fit and reshape now correctly support
moveable-but-not-copyable types such as unique_ptr. Correction to
compiler support checks for sort.
- 2023-10-10: v7.32 - Remove needless MSVC macro definitions as aligned_storage is no longer used (deprecated in C++23).
- 2023-08-24: v7.31 - Update to sort algorithm, uses less memory for trivial/movable types smaller than
sizeof(value_type *) * 2, no performance difference.
- 2023-08-10: v7.30 - Breaking changes: plf::colony_limits changed
back to plf::limits, advance/next/prev no longer bound to
end()/cend()/rbegin/crbegin(). If you think a use of these functions
may go beyond those locations, check using the < or <= operators
and do the bound yourself.
Iterators do not have access to the end/begin iterators of a colony, so
neither do the advance/next/prev functions. The unneeded metadata
removal below forces this change but the reduction in memory usage is
deemed more important.
Largely-unneeded group metadata variable removed, code fixed to suit.
Overall performance benefit, particularly for small scalar types.
noexcept removed on colony(block_limits) and colony(block_limits,
allocator) due to lakos rule.
Various code fluff and minor corrections.
Fix to is_active() when a group is deallocated from the hive, but then
the same pointer address is re-supplied to the hive via the allocator
for a new group, and is_active is called with an iterator pointing to
an element in the old (deallocated) group.
- 2023-07-05: v7.20 - Bypass buggy MSVC /W4 warning, comment corrections.
- 2023-06-23: v7.19 - Improvement for support on older compilers.
Correction to logic and optimisations for unique() and
std::erase_if/std::erase overloads.
- 2023-06-13: v7.18 - Less codegen when exceptions are disabled but
types aren't nothrow. Corrections to some noexcept qualifiers on fill
patterns.
- 2023-06-08: v7.17 - Technical correction to casting for pointers
and casting pointers to void *. Minor optimisations to unique() and
erase_if overload.
- 2023-05-22: v7.16 - correction to group constructor for c++03/98.
- 2023-04-30: v7.15 - max_block_capacity_per_allocation renamed to
the more intuitive max_elements_per_allocation.
max_elements_per_allocation now returns 0 if return value is below the
colony hard minimum block capacity limit.
- 2023-04-22: v7.13 - Performance improvement for overaligned small
types. Addition of max_block_capacity_per_allocation function, to allow
people using allocators which can only supply a fixed or low maximum
amount of memory for any one allocation (eg. embedded) to correctly
assess what their maximum block capacity should be, if they don't want
to go over those limits. Correction to block_allocation_amount
function. Both of these functions truncate to the hard max block
capacity limit of colony ie.
numeric_limits<skipfield_type>::max(), so, 255 for types with
sizeof < 10, 65535 for others.
- 2023-02-15: v7.11 - Correction of internal namespacing for iterator
subtypes to avoid external namespace mis-matches. Correction to test
suite under c++03/98. Minor performance improvement to range erase.
- 2023-02-12: v7.10 - Correction to distance overload.
- 2023-02-03: v7.08 - More accurate compiler/library detection for
C++20 support, C++20 support disabled for apple clang as it is not as
up to date as non-apple clang.
- 2023-01-26: v7.07 - Fix to reverse_iterator(iterator) constructors and '= iterator' operators.
- 2023-01-11: v7.06 - Correction to C++03 support. Correction to
colony_data() struct specification. Support for disabling exceptions
under GCC, Clang and MSVC. Will (a) now compile under gcc/clang when
-fno-exceptions is specified and (b) will terminate in cases where
exceptions would normally be thrown.
- 2022-11-30: v7.04 - Workaround redefine macro warning.
- 2022-10-05: v7.03 - Correction to C++03/98 support when using 8-bit types.
- 2022-10-02: v7.02 - Correction to move constructor. Removed
std::aligned_storage (this is deprecated in C++23) and corrected logic
in aligned storage types. Correction for older compilers which
partially support C++11 like MSVC2010.
- 2022-09-03: v7.01 - More tooling sharing between plf:: headers.
Some reinterpret_cast's corrected to convert_pointer ie. corrections to
data(), range-erase and C++03 group constructor when non-trivial
pointer types used. convert_pointer now uses std::bit_cast instead of
reinterpret_cast, to allow for potential constexpr use in future.
- 2022-08-27: v7.00 - Bring colony in line with bugfixes, correctness changes and additional features for plf::hive:
Minor optimisation to sort.
Explicit-ness constructor corrections.
Change 'block_limits()' to 'block_capacity_limits()'.
Addition of 'block_capacity_hard_limits()'.
Added std::type_identity_t to allocator copy constructor overloads.
Correction to next and prev ADL overloads.
Improvement to erase_if algorithm.
Addition of unique().
Removal of range-based sentinel overloads for constructor, insert,
assign (these are covered by the C++20 ranges v3 overloads).
trim() changed to trim_capacity (trim has a specific meaning in some
parts of the standard library). Addition of trim_capacity(n).
skipfield_type switching changed to be partially based on element_type
sizeof.
Addition of is_active(const_iterator).
Corrections to distance, advance, reshape, trim_capacity, unique,
block_capacity_hard_limits, splice.
Corrections to erase to allow get_iterator to work correctly.
Corrections to exception recovery in range assign, range insert, range
constructor.
Splice now retains original reserved memory blocks in both source and
destination post-operation.
Const_iterator and const_reverse_iterator can no longer be converted
into iterator and reverse_iterator respectively (under C++11 and above
- C++03 and below do not support this functionality).
Return type of const_reverse_iterator::base() is now a const_iterator
instead of an iterator.
rbegin/rend/crbegin/crend no longer segfault when calling .base() on an
empty hive.
Changes to allocator rebinds to allow use with pmr allocators.
Default maximum capacity changed to 8192 as per benchmark results.
default_min_block_capacity, default_max_block_capacity and
default_block_capacity_limits functions added.
Correction to splice to allow get_iterator and is_active to work.
Corrections to get_iterator in situations where the iterator/pointer
points to a block which has been removed then added back into the
iterative sequence (via either unused_groups or an allocator), but now
points to an element after end().
Optimizations to splice, get_iterator.
Conformance changes for iterator/reverse_iterator.
Compatibility with std::reverse_iterator added (for use with rangesv3).
Correction/optimisation to range erase.
Change to group numbers strategy - never update unless overflow
possible- which is a 1 in numeric_limits<size_type>::max() event.
This removes a O(n) factor in erase() when there is a large number of
groups.
Singly-linked groups-with-erasures intrusive list changed to
doubly-linked to avoid O(n) performance factors with large numbers of
small blocks.
Corrections to allocator rebinds.
Correction to pointer conversions for non-trivial pointer types.
Iterators moved to bottom of file to make human parsing easier.
Added plf::ranges::from_range_t for use in rangesv3 constructors until
such point as std::ranges::from_range_t becomes more widely available
in libraries.
Correction to free list writes to make compliant with C++ standards
rules (though will have no noticable effect for bulk of situations).
Correction to exception safety for reshape().
Fix for situations with 128-bit platform when using char as
element_type.
Minor optimization to group allocations under some compilers.
Minor correction to fill-insert functions/constructors.
range erase now returns iterator in case of situation where end() is
supplied as last in a loop and return value is necessary to make sure iterator == end() end condition is reached.
Comment updating.
Some tooling functions made public for access across multiple plf:: libraries.
Other minor code reductions.
Correction to copy constructor.
- 2021-12-11: v6.33 - Added spaceship operator for three-way
comparison of colonies. block_metadata_memory() added as a convenience
function, for now.
- 2021-10-31: v6.32 - Range constructors/inserts/assigns updated so
that the slower form that is required to match sentinels, will not
match iterator types which can be converted to one another eg.
const_iterator and iterator. This means that, for example, a call to
range-assign using colony's const_iterator and iterator will be able to
use colony's faster ADL distance() overload rather than just doing a
straight for-loop to determine length of range (necessary with
sentinels, as there is no overload for distance() for sentinels).
- 2021-10-26: v6.31 - Comment updating.
- 2021-09-18: v6.30 - Correction to range constructor/insert/assign
with differing iterator types. Correction to compiler feature
detections.
- 2021-09-08: v6.29 - Removal of hive typedef (hive now has it's own
separate codebase at https://github.com/mattreecebentley/plf_hive.
Corrections to test suite.
- 2021-06-28: v6.28 - Clear() behaviour changed - now retains all
memory blocks in reserved pool, rather than deallocating them. reset()
introduced, which replicates old clear() functionality (destroy
elements + deallocate blocks). Alternatively to deallocate blocks you
can follow clear() with shrink_to_fit() or trim(). Bug in ->
operator for reverse_iterator fixed.
- 2021-06-21: v6.26 - Added support for differing iterator types (eg.
using sentinels or const_iterator and iterator) in range constructor.
- 2021-06-02: v6.25 - Comment updating.
- 2021-05-26: v6.24 - Added sentinel support for assign. Correction to get_iterator under C++98/03.
- 2021-05-25: v6.23 - Correction to compiler detection routines for clang/gcc running in MSVC environment.
- 2021-05-20: v6.22 - Correction to compiler detection routines for clang - only libc++ 13 and above support the concept library.
- 2021-05-09: v6.21 - Minor code reduction, corrections to splice
(now throws if source memory blocks are outside destination's memory
block capacity limits).
- 2021-04-30: v6.20 - Changed optimization strategy for 3/4-way
decision patterns in erase/insert/emplace. Previous strategy worked
better on earlier compilers, however seems to be better with straight
if statements for modern clang/gcc. Correction to move-insert.
- 2021-04-02: v6.17 - get_iterator_from_pointer changed to
get_iterator - the pointer part is implied by the fact that it's the
only argument. Added get_const_iterator - both take a const_pointer,
the latter returns a const_iterator. Correction to rbegin() and rend()
const status.
- 2021-03-22: v6.16 - Update to container based on LEWG feedback.
plf::limits becomes plf::colony_limits. Correction to MSVC compiler
CPP20 support.
Instead of taking an unsigned integer type as a parameter, the colony
template now takes a (basically boolean) plf::priority enum parameter,
allowing one to choose between plf::performance (equivalent to unsigned
short - default - in previous versions of colony) and plf::memory_use
(equivalent to unsigned char in previous versions of colony). There was
never any point to choosing a higher bit-depth unsigned integer type
anyway (see Group sizes in FAQ above).
Publicly-accessible skipfield_type parameter removed.
Correction to noexcept statuses on some functions when variadics unsupported by compiler.
Removal of needless function call in constructors when alignment is supported by compiler.
Addition of range insert when using different types of iterators which
are equality_comparable, under CPP20. ie. support sentinels and
comparisons between const_iterators and regular iterators.
plf::hive, plf::hive_limits and plf::hive_priority are alternate
typedefs for plf::colony, plf::colony_limits and plf::colony_priority
respectively (anticipating a possible name change for the std:: version
of colony). These are only available in C++11 and above, as C++03 and
below do not support typedefing of templates.
data() function reintroduced, now provides bitfields for SIMD usage.
- 2021-01-13: v6.11 - Reduction of compiler feature macros for
reasons of readability, code size and convenience of updating between
the different containers. Hopefully, PLF_ by itself will be enough to
disambiguate these from similarly-named macros. If not, will revert
back. Improvement of a few compiler rules. Correction to
shrink_to_fit/reshape. Consolidation of catch recovery code for
range_fill/fill and range_fill_skipblock/fill_skipblock.
- 2021-01-11: v6.10 - Corrections to compiler feature detection.
- 2021-01-09: v6.09 - Correction to group allocations under C++98/03. Removal of unneeded static_casts.
- 2021-01-08: v6.08 - Corrections to distance() under C++98/03 (undefined behaviour).
- 2021-01-07: v6.07 - Corrections to noexcept specifiers, courtesy of cppcheck.
- 2021-01-06: v6.06 - Increase of 6%-10% speed under GCC 9/10 in
high-modification general-use benchmarks (mitigation of gcc
optimisation bug).
Correction to exception handling in reserve. Removal of code
redundancies & code reduction.
Under GCC 8, 1.5% faster insertion and 2.5% faster erasure in small
struct benchmarks.
- 2021-01-03: v6.05 - Better support for type alignment courtesy of
Tomas Maly (https://github.com/malytomas). Resultant performance
improvement of 2% in high-modification benchmarks. plf::pcg_rand
renamed to plf::rand, modified to enable better support for C++03 and
lower compilers. Correction to support under c++03/98.
- 2020-12-26: v6.04 - Corrections to compiler feature detection code.
Test suite now uses plf::pcg_rand instead of xor_rand. Minor correction
to overalignment code (more to come in future).
- 2020-11-29: v6.03 - Optimization to destroy_all_data (destructor/clear/move).
- 2020-11-28: v6.02 - Default value fill constructor added. Reserve
now throws instead of auto-correcting capacity value if it is greater
than max_size().
- 2020-11-06: v6.01 - Correction to noexcept guarantees for splice.
Addition of std::erase() and std::erase_if() non-member function
overloads for colony container.
Range-erase now returns iterator to the element after the erased range,
or if the end of the erased range is end(), returns end().
Typedef and macro tidy up.
Correction to overaligned element support.
Removal of some unneeded asserts.
- 2020-10-26: v6.00 - Overall re-write to be more in line with
proposed STL addition. Correction to edge case optimization in
distance() + additional minor optimizations. Fill-constructor changed
to be explicit.
Change of crbegin(), rbegin(), crend() and rend() to be noexcept (adds
minor performance cost to rbegin() and crbegin()). Additionally, now
(rbegin() == rend() && crbegin() == crend()) when container is
empty - important for loops.
Distance, next/prev and advance are now non-member functions, MSVC2013
support is removed (MSVC2013 has an unfixed bug to do with templates
which prevented making these functions non-members originally -
previous and subsequent versions of MSVC versions do not have the bug).
get_index_from_iterator is removed, please use distance(colony.begin(),
iterator) instead. get_iterator_from_index is removed, please use
"iterator = begin(); colony.advance(iterator, index);" instead.
get_iterator_from_pointer is now noexcept.
reserve() is now a fully-functioning ie.
multiple-memory-block-reserving reserve function, and insert will take
advantage of this. Erase will now reserve some but not all memory
blocks which have all elements erased. Trim() function introduced,
which removes unused reserved memory blocks without causing
reallocation.
assign() - both fill, range and initializer-list versions - are added.
Performance improvements in multiple areas, particularly fill-insert,
range/initializer-list insert, fill/range constructors and operator =.
Comment corrections. Some asserts changed to static asserts.
set_block_capacity_limits() renamed to reshape().
get_block_capacity_limits() renamed to block_limits().
set_minimum_block_capacity() and set_maximum_block_capacity() removed,
use a combination of block_limits() and reshape() instead.
- 2020-10-25: v5.43 - Removal of problematic asserts in operators --
and ++. Change of name from approximate_memory_usage() to memory().
- 2020-09-25: v5.42 - Correction to technically undefined behaviour under C++98/03.
- 2020-09-21: v5.41 - Correction to splice.
- 2020-09-19: v5.40 - Correction to non-member swap, should've been in namespace std.
- 2020-09-17: v5.39 - Removal of destructor calls within sort() since
all element locations inevitably get written to in the container/array
so any necessary destructor calls for non-trivial objects will be
handled by the move/copy operators of that element type.
- 2020-09-16: v5.38 - Removal of unnecessary branch checks in sort(), thanks to sentinel reduction, courtesy of github user morwenn.
- 2020-08-16: v5.37 - Re-included sort(), using the indiesort variant
(higher performance for larger types and significantly-reduced memory
usage). Uses std::sort internally but will use another sort function if
it's name (including namespace) is defined as the macro
PLF_COLONY_SORT_FUNCTION before including the colony .h. Supplied sort
function must take same parameters as std::sort.
- 2020-08-15: v5.36 - Correction for edge case within range erase. Correction to range insert in compilers without type traits.
- 2020-07-07: v5.35 - Range-insert/constructor optimization now available in C++11-and-above modes.
- 2020-06-27: v5.34 - Fixes to distance, set_block_capacity_limits. Reduction to compiler switches.
- 2020-05-03: v5.33 - Minor optimisation to operator ==. Some internal iterator usage changed to const_iterator.
- 2020-04-26: v5.32 - Correction to <=> iterator operator, some
static_cast's to avoid additional MSVC warnings. Fix for minor
regression in prev version.
- 2020-04-24: v5.31 - Shifted some code out of the insert functions
into a separate function, which improves performance for mixed-code
scenarios like the test suite, while providing no performance detriment
in the higher complexity tests. Fix to small problem with conversion
warnings in fill-insert.
- 2020-04-16: v5.29 - Correction to operator = && when
pointers as supplied by an allocator are non-trivial. Update some
comments. Optimization for fill-insert with non-trivial types.
- 2020-04-13: v5.28 - Fixed an issue with prior range insert
optimisation which would've caused reallocation of elements and
iterator invalidation under some scenarios. Minor optimisation to
reinitialize() based on most common use-case.
- 2020-04-10: v5.27 - Corrections to test suite. Added [[nodiscard]] to empty().
- 2020-04-08: v5.26 - Added default-value fill constructor (eg.
'colony<int>(14)' to create an int colony with 14
default-constructed ints). Changed names of change_group_sizes,
get_group_sizes, change_minimum_group_size and
change_maximum_group_size to: set_block_capacity_limits,
get_block_capacity_limits, set_minimum_block_capacity and
set_maximum_block_capacity. This is to bring the implementation more in
line with the C++ standards proposal and to make the naming more
independent of implementation, and more correct. Removed
'const_iterator get_iterator_from_pointer(const const_pointer)', as
users can manually cast the pointers themselves to 'iterator
get_iterator_from_pointer(const pointer)', and the return type will
automatically cast from iterator to const_iterator if a const_iterator
is used to receive the return value. This also brings the
implementation more in line with current C++ standards. Added
get_reverse_iterator_from_pointer() and
get_reverse_iterator_from_index(). Corrected missing macro undef in
previous version. Changed get_raw_memory_block_pointers() to data(), to
be more in line with std library.
- 2020-03-22: v5.25 - Added colony operator = for
std::initializer_list. Updated noexcept conditions for swap and move
operations. Added const_pointer overload for
get_iterator_from_pointer(). Added code to automatically reserve
necessary capacity in range/initializer_list insert/construct/operator
=, if the range in question uses random_access iterators. Added
spaceship operator (why) for compilers which support it.
- 2019-11-27: v5.24 - Removed unneeded assert for iterator operator =
when assigning between const and non-const iterators. Added operator =
and copy constructor for assigning/constructing between const and
non-const reverse iterators. Increased ability for reverse_iterators
(const and non-const) to take assignment from regular const/non-const
iterators.
- 2019-11-26: v5.23 - Correction to iterator operator = when
assigning between const and non-const iterators. Correction to begin()
and end() to support pre-C++11 semantics ie. can return const_iterator
as an overload. Which in turn allows colony to function with eric
neibler's ranges implementation.
- 2019-11-18: v5.22 - Correction to edge-case in advance(), slight
speed increases to iterator operator ++, insert, emplace. Changes to
remove warnings in test suite. Overall 1% performance improvement in
general use benchmarking, 4-5% performance improvement in general use
benchmarking when dealing with low numbers of elements and low amounts
of modification. Improvements partially based on advice about pointer
aliasing from Elliot Goodrich.
- 2019-08-13: v5.21 - Fix for MSVC2019 in permissive mode incorrectly
reporting a warning of use of std::allocator instead of
std::allocator_traits
- 2019-08-01: v5.20 - Edited skipfield pattern to enable parallel
conversion to SIMD-gather mask (erased skipfield nodes in middle of
skipblocks will always be non-zero now). Added function
get_raw_memory_block_pointers() to enable users to supply elements
directly to SIMD-gather/scatter operations using the skipfield as a
mask (skipfield will require conversion to specific SIMD instruction
set format, which can also be accomplished in SIMD, in parallel). Tests
added to test suite for both non-trivial types, and the
get_raw_memory_block_pointers() function. Corrections to fill-insert
for aligned types. Minor correction to avoid type safety warning in GCC
under C++03 and using "-Werror=sign-conversion".
- 2019-06-17: v5.11 - Explicitly specified some implicit type
promotion conversions in order to deal with errors when using GCC with
"-Werror=conversion". Added non-copyable type test to test suite.
- 2019-06-11: v5.10 - Correction to reserve() semantics. Reserve()
also will no longer assert that reserve amount is within bounds of
maximum and minimum group sizes, and will silently round the value down
or up accordingly. Please consult the documentation to understand the
current limitations of reserve() for colony.
- 2019-04-15: v5.09 - Constexpr added to type traits 'if' blocks and
some other scenarios, for compilers which support it - including
MSVC2017 with std:c++17 switch. This fixes some issues for
movable-but-not-copyable elements, and creates performance benefits in
some scenarios. May also speed up compile times slightly.
- 2019-04-12: v5.08 - shrink_to_fit(), reserve(),
change_group_sizes(), change_minimum_group_size() and
change_maximum_group_size() are now valid operations for element types
which are move-constructible but not copy-constructible, when type
traits are supported by compiler. These operations will also be faster
for non-trivially-copyable-but-trivially-movable types, if reallocation
of existing elements is triggered.
- 2019-03-19: v5.07 - Removed unnecessary const casts (to avoid GCC
warning) and added newline at end of file (to avoid clang warning).
- 2019-02-28: v5.06 - Added static_cast's to work around GCC's -Werror=sign-conversion warnings.
- 2019-01-30: v5.05 - Bizarre minor redundancy removal. Add post-move assignment test to test suite.
- 2019-01-16: v5.04 - Correction to library detection features to
include type traits for libc++. Removed support for plf::timsort, added
support for gfx::timsort (differences between plf and gfx version were
not substantive enough to justify maintaining a fork of the original
code).
- 2018-11-16: v5.03 - Correction to max_size() for use with allocator_traits and to be in line with C++20.
- 2018-10-28: v5.02 - Optimization to move assignment - this also
improves regular assignment, sort, splice, swap, change_group_sizes,
shrink_to_fit & reserve.
- 2018-10-08: v5.01 - Comment corrections, blank() no longer
differentiates based on compiler (re-testing revealed this is best
strategy across compilers). Correction: included header for offsetof.
- 2018-10-02: v5.00 - Change of skipfield type from high-complexity
jump-counting skipfield (previously known as 'advanced jump-counting')
to low complexity skipfield (previously known under working title of
'Bentley pattern'). Change of erased-element-memory-location storage
mechanism from free-list of erased element locations, to free-list of
blocks of consecutive erased element locations. Resultant procedural
change means that all singular insert/emplace and erase operations now
have O(1) time complexity, while multi-insert is O(n) and multi-erase
is O(n) for non-trivially-destructible elements, ~O(log n) for
trivially-destructible elements (see time complexity in the faq).
In addition iteration will generally be faster in situations where
elements are being inserted and erased a lot, as skipblocks can no
longer get split up into multiple skipblocks by insert, mean there are
less overall 'jumps' during subsequent iteration. Also since insertion
and erasure can no longer result an an unpredictable skipfield update,
the container is much more suitable for extremely-low-latency
environments. <, >, <= & >= iterator operators and
operations which use them e.g. range-erase in debug mode, no longer
throw exceptions if supplied with begin() and end() iterators of an
empty colony. Other corrections to range-erase. Optimization to
fill-insert. More extensive testing for range-erase and fill-insert
added to test suite. Platform-specific code removed for iterator
operator ++ (default now best across all platforms). Range-erase and
fill-insert 10% faster overall in tests. General-use-case testing up to
10% faster on core2 (4.5% faster on average).
- 2018-07-12: v4.62 - Optimization to swap for when the allocator supplies non-trivial-but-movable pointers.
- 2018-07-07: v4.61 - Optimization to swap. Updating of some CPU-specific tests. Comment correction/updates.
- 2018-07-06: v4.60 - Multiple corrections to nothrow_constructible
checks under insert/emplace. Addition of second emplace test to test
suite. Added void * casts to deal with GCC 8.1's garbage warning
messages around memset. Update/addition of comments. Minor update to
benchmark suite.
- 2018-06-27: v4.59 - Change of sort dereferencer function to allow
for non-const sort functions (with internal state for example).
- 2018-06-19: v4.58 - Corrections to test suite compiler feature
detection macros, change reverse_iterator constructor type to
non-explicit, minor optimization to insert for
non-trivially-constructible types, minor code-comment/code cleanup.
- 2018-05-09: v4.57 - Mitigated NULL == 0 warning for clang, fixed
compiler feature definitions for clang + libstdc++, thanks to
bluebear94.
- 2018-05-02: v4.56 - Same optimization for GCC & clear/splice/etc now applied to other compilers generically.
- 2018-04-28: v4.55 - Postcondition of source colony for
move-assignment/construction is the same as an empty colony now (i.e.
you can use it normally post-move without undefined behaviours). Minor
optimisation to move-assignment/construction and several other
functions (splice, clear, range-erase) as a result under C++11 and
above (when allocator does not supply smart pointers). Minor
optimisation to swap; the original C++03 code was faster than the C++11
move-swap code under C++11. Minor optimisations to distance, advance.
Code comment cleanups. It is now valid behaviour to call range-erase
with two equal iterators i.e. an empty range.
- 2018-04-13: v4.51 - Mistake in NOEXCEPT_MOVE_ASSIGNMENT compiler feature macro, fixed.
- 2018-04-02: v4.50 - Stack-based erasure-recording system replaced
with per-memory-block index-based free list + erasures-groups-list
structure. Resultant speed up of 10% in high-modification general-usage
benchmarks, 17% reduction in code size, and reduced memory usage. This
also makes erase exception-safe (no allocations due to no stack) unless
destructor of object throws exception (i.e. fails to close a file lock,
or whatever) or an invalid/uninitialized iterator is supplied to
function. Reversion of insert from function call to emplace, back to a
separate function - as this was causing copy-construction on
non-trivial types, leading to additional temporaries and severe
performance drop on large types. General code cleanup and renaming.
Corrections to compiler feature support detection. Corrections to some
noexcept function statuses. Minor optimisations for C++03/98 and in
general. Minor optimisation to operator = under c++11 and upwards.
Support for over-aligned types.
- 2018-01-05: v4.14 - Minor optimization to insert.
- 2017-11-15: v4.13 - One noexcept change, fill-insert correction/optimization, minor optimizations and code comment cleanup.
- 2017-11-1: v4.12 - Correction to no-exception compile-time checking
for insert/etc. get_iterator_from_index() now templated, supports
multiple index types. This also reduces codegen when both this function
and advance() are unused. Change to some inline hinting.
- 2017-10-11: v4.11 - Codegen reduction for insert, move-insert for compilers with variadic parameter support.
- 2017-10-03: v4.10 - Rollback of a previous insert optimization due
to potential for overflow with extremely large numbers of elements and
extremely large numbers of erasures. Improvement to range-erase
performance.
- 2017-09-26: v4.09 - Large single-insertion performance improvement
for small scalar types. Other minor optimizations to splice,
range-erase and advance. False-negative removal in test suite for
32-bit compilers.
- 2017-09-16: v4.07 - Improved fill-insert performance for
trivially_copy_constructible types under C++11/C++14/etc. Avoid
generating exception try-catch code for nothrow-constructible types.
Correction to reserve() - people were probably calling it with
size_type's, causing it to truncate/overflow. Minor correction to type
traits use in sort(). Minor optimization to operator --.
- 2017-09-11: v4.06 - Corrections to fill-insert. Optimization for
reserve() followed by fill-insert. Removal of return values from
fill-insert, range-insert and initializer-list insert (no point,
unordered insertion, always).
- 2017-08-31: v4.05 - void splice(colony &source) added to
colony. This means you can move all elements from one colony into
another colony of the same type without invalidating pointers or
iterators to the source elements. Splicing is also much faster than
range-moving the elements. Splice does not guarantee appending to the
destination colony - the insert location of source groups is chosen
based on the most positive overall performance outcome for subsequent
iteration and insertion.
- 2017-08-26: v4.01 - Same optimization as v4 applied for
skylake/kabylake CPUs under GCC and -march=native. Unlike haswell, this
is associated with a small decrease (~1%) to unordered use-case
performance, but the same 15-26% performance improvement for iteration
tests. Further feedback from external testing welcome. Redundant
iterator parameter removed (allocator). C++14-specific const/non
iterator comparisons (e.g. if (reverse_iterator !=
const_reverse_iterator)) now available for all compilers and C++
versions. Correction to benchmark suite.
- 2017-07-26: v4.00 - Up to 7% iteration performance improvement on
Core2 processors and/or under MSVC, 15%-26% iteration performance
improvement on pre-"kaby lake", post-"Westmere" Core i processors
(haswell, broadwell etc) processors under GCC (with -march=native
enabled). Amount of improvement depends on number of elements. Overall
2% improvement in modification use-case testing on all platforms.
Correction to fill-constructor and initialization-list constructor.
Thanks to Phil Williams and Jason Turner for testing for me on alt
processors!
- 2017-06-21: v3.95 - Corrected support for GCC
v5.x. Correction to test suite under GCC versions > v5. Correction
to distance() for reverse iterators.
- 2017-06-01: v3.94 - Minor optimizations and test suite cleanup.
- 2017-05-21:
v3.93 - Added sort(). Colonies can now be sorted as you would with a
list, with or without a supplied comparison function (less-than if
without). Removed MSVC warnings at level 4, ignoring those which're
obviously compiler bugs. More support for non-gcc compilers using gcc
libraries or libc++.
- 2017-05-11: v3.91 - Additional type
safety check on stack consolidate. Move assignment now follows C++17
noexcept rule. Correction to missing undef's at end of header.
- 2017-05-11:
v3.90 - Minor optimizations to initializer-list insert and copy
constructors. Emplace availability correction for some compilers.
Corrections to shrink_to_fit() and reserve() (will not longer go below
minimum group size). Minor optimizations to operator = and c++03 swap.
Other minor code improvements.
- 2017-05-06: v3.89 - Minor correction to noexcept statuses. Correction to test suite under C++03.
- 2017-03-28:
v3.88 - Correction to emplace. Corrections to default constructor to
allow for empty initialization lists. Some standards compliance updates
and corrections to noexcept statuses. skipfield_type is now a
publicly-accessable member typedef. get_group_sizes() is now available.
Allocator-extended copy and move constructors added. get_allocator()
added. swap(colony &A, colony &B) is now non-member and
non-friend.
- 2017-02-08: Update and corrections to benchmark code and test
results.
- 2016-12-10: v3.87 - Optimized and corrected range erase. Documentation
updated.
- 2016-11-19: v3.86 - Performance improvements for low numbers of scalar
types. Minor optimizations for fill-constructor and initializer-list
constructor. Corrections to advance.
- 2016-11-12: v3.83 - Minor optimizations. Edge-case corrections for
advance functions and copy constructor. Optimizations to
get_index_from_iterator, get_iterator_from_pointer, distance, advance.
Advance now correctly bounds to rbegin and rend for reverse iterators.
Warning removal for test suite.
- 2016-11-1: v3.81 - Optimizations to insert functions. Corrections to
fill-insert/fill-construct functions. Minor correction to internal stack
copy constructor. Some function and comment tidyup. Moved referencer test
code out from plf_bench.h to individual test files due to MSVC's forward
declaration bug (referencer tests not possible with MSVC for this reason).
Possible edge-case out-of-bounds memory access for insert removed.
Benchmarks updated.
- 2016-10-27: v3.80 - Further optimizations. Removed a potential memory
leak which would only occur upon exception-based state rollback within
insert functions. Update to benchmark suite, addition of packed_deque
container and associated tests.
- 2016-10-15: v3.76 - Removed potential memory leak in internal stack
mechanism.
- 2016-10-14: v3.75 - Added get_index_from_reverse_iterator(). Further
optimization (and one minor correction) of the reduced_stack storage
mechanism , leading to an 8% performance increase in general_use benchmarks
for small structs. Additional minor optimization for C++03. Some code
comment tidyup.
- 2016-10-10: v3.73 - change_group_size functions no longer copy-construct
into a new colony unless the stack is not empty, and either min_group_size
is larger than the smallest group in the stack, or max_group_size is
smaller than the largest group in the stack. Correction to
change_group_sizes code (was clearing erased locations unnecessarily).
Reinitialize function added, which supports the changing of group sizes for
colonies of non-copy-constructible element types. Emplace changed to no
longer require move semantics, which enables the use of
non-move-constructible/non-copy-constructible types with colony (example:
anything containing a std::mutex). Minor correction to colony test suite
under C++03.
- 2016-10-04: v3.72 - minor fix to erase.
- 2016-10-03: v3.71 - Replaced all but one vectorizing skipfield update
with memmove ops for greater performance. Colony is no longer dependent on
plf::stack, now has it's own reduced-functionality internal structure.
TLDR, slightly faster, slightly faster build time & slightly less
memory use. Colony and stack are no longer friends :( (aw). Updated
documentation. Stack separated out of colony package and test suite and
vice-versa. Added functions to convert element pointer to iterator, and to
convert iterator to index and vice-versa. Removed pointer-based erase
function (use get_iterator_from_pointer() instead and call erase() with the
resultant iterator). Minor update to distance, advance, prev and next
functions. Benchmark suite updated.
- 2016-09-02: v3.61 - Slight performance improvement for general-use-cases
for colony, small performance/usability improvements in benchmark suite.
Tweak for MSVC2010 performance. Correction to stack emplace.
- 2016-08-24: v3.6 - 8% speedup on iteration, vs v3.55, for colony
with larger-than-scalar types. Performance increases and minor corrections
in benchmark suite.
- 2016-08-20: v3.55 - Updates to benchmark suite - now uses a faster
xorshift-type rand generator and a fast_mod function, test differences
between containers more obvious now. Memory approximation also now outside
of main loops, test cases updated for general_use test. Entirely new
test-case function. Minor performance enhancements to
insert/erase/operator++ for colony + code tidy-up. Minor warning removal
for test suite.
- 2016-08-04: v3.51 - Correction to move-insert courtesy of Peet Nick.
Removal of end-block edge-case scenario code, as it was found to be of such
low statistical significance as to be useless. The fix increased memory use
in the scenario of the edge case which might be it's own problem in most
scenarios. To get around the edge case, if it occurs in a given context, an
allocator approach would be most appropriate. Update to benchmark
suite.
- 2016-07-19: v3.5 - Colony now accepts a template parameter for the
skipfield type. This enables the use of, for example, unsigned char as the
skipfield type. The bitdepth of the unsigned integer also defines the
default maximum size of colony groups. The benchmark suite has been updated
with memory measurements for the general_use tests. General_use tests
changed to percentage-based tests. Internal erased location stack now
stores only element pointers, not full iterators. Storing just the pointer
and having to reconstruct the iterator slows down reinsertion after an
erase, but speeds up the erase itself and results in an overall performance
improvement, as well as less memory consumption. Slight improvement for
fill-insert. Sanity-checks for range-insert and initializer-list-insert
implemented. Minor fix to C++03 support in benchmark suite.
- 2016-07-4: v3.35 - Another compliance fix for benchmark suite in clang,
courtesy of Arthur O'Dwyer.
- 2016-07-3: v3.34 - Minor warning removal for test suite. Performance
improvement for colony edge-case scenario where a single element is
inserted and then erased repeatedly, and where the insertion point happens
to be at the end of a memory block.
- 2016-07-1: v3.33 - Empty destructors/constructors removed in iterators.
Small compliancy fixes in both colony and benchmark suite. Thanks to Arthur
O'Dwyer for this update.
- 2016-06-25: v3.31 - Colony iterators no longer inherit from std::iterator
and implement the required typedefs themselves. Code tidyup and minor
changes. Default of 1 implemented for prev/next.
- 2016-06-17: v3.30 - Correction to colony range constructor. Corrections
to advance() asserts.
- 2016-06-15: v3.29 - Support for stateful allocators added, to both colony
and stack. More generic solution applied for preventing calls for
fill-insert to be matched by range insert template.
- 2016-06-14: v3.25 - Edge-case corrections to colony's clear(),
range-insert and fill-insert functions. Minor performance improvement in
erase edge-case. Removed older (colony-specific) range insert. Simplified
constructors.
- 2016-06-12: v3.22 - Range, fill and initializer-list based insert()'s and
constructors now implemented in colony. Bugfix for Microsoft compilers.
Warnings fix for clang. Reinitialize functions removed, replaced with
change_group_sizes(), change_minimum_group_size() and
change_maximum_group_size().
- 2016-06-11: v3.19 - Minor bugfix to plf::stack.
- 2016-06-9: v3.18 - Corrections to colony and stack C++11 typedefs. Some
code tidyup. Minor code corrections. Simplified reserve() and
shrink_to_fit() functions. Added trim_trailing_groups() function to stack.
Minor performance improvements.
- 2016-05-31: v3.16 - Corrections to colony and stack reserve(). Some code
tidyup. Correction to test suite.
- 2016-05-30: v3.15 - Colony and stack are now compliant with C++11 and
C++14 container
concepts. Vectorized some erasure and insertion operations resulting in
better overall performance in some scenarios. Corrected edge case in
reverse iteration operator ++. All iterators now bounded by asserts in
debug mode. Correction to capacity functions.
- 2016-05-26: v3.14 - Added swap (std::swap worked fine without it, mainly
required for standards compliance, also is exception-safe) and max_size()
functions to stack and colony.
- 2016-05-24: v3.13 - erase(element_pointer) added to colony. This enables
erasure via a colony element's pointer, rather than it's iterator. Slightly
slower than iterator-based erasure as a lookup has to be done for the
colony element's group. Update to test suite.
- 2016-05-19: v3.11 - Fix for colony shrink_to_fit(), added special case to
stack copy constructor for when source size > max_group_size, colony and
stack constructors now explicit. Update to test suite.
- 2016-05-12: v3.10 - Both stack and colony no longer preallocate upon
construction, only upon first insertion. Minor assert bugfix in colony.
shrink_to_fit(), reserve() and capacity() functions added to both classes.
Some code cleanup, corrections for C++03 and minor optimizations.
- 2016-04-28: v3.05 - Removal of compiler-specific iteration code,
resulting in 8% speedup for larger-than-scalar type iteration, 6% slowdown
for scalar-type iteration, under GCC x64. MSVC unaffected by change.
Addition of benchmark suite. Correction to plf_nanotimer under
linux/bsd.
- 2016-04-16: v3.04 - Corrections to reinitialize asserts. Added
bound-checking asserts to advance/next/prev implementations.
- 2016-03-26: v3.03 - Correction to operator = on colony. Replaced
SDL2/SDL_Timer in benchmarks with plf_nanotimer, a cross-platform
~nanosecond-precision timer. Correction to end() and begin() overloads -
internal begin/end iterator could previously be altered by user activity,
in some cases. Correction to .next functions.
- 2016-03-24: v3.02 - Small performance improvements. Fix for demo for
regular SDL2 usage. Duplication of macros from plf_stack.h to plf_colony.h
to fix issue when plf_stack.h is also used within project separately from
plf_colony.h.
- 2016-02-23: v3.01 - Colony now uses a jump-counting
skipfield instead of a boolean field, which mitigates worst-case
scenario performance by factors of ten. Iterators now bidirectional (but
include > < >= and <= operators) instead of random-access, and
compliant with C++-specification's time-complexity requirements (all
operations O(1) amortised). +=, -=, - and + iterator operators relegated to
advance, distance, next and prev functions under colony. There is greater
compliance with allocators. Group size now limited to 65535 max for colony,
to decrease memory wastage and improve skipfield performance. Various
bugfixes and corrections. plf::stack storage limit no longer 32-bit uint
max (relies on allocator to supply correct size_type). Added worst-case and
best-case scenario tests to colony benchmark, and added std::stack
comparison to plf::stack benchmark. Benchmarks yet to be updated in
docs.
- 2015-11-20: v2.34 - Correction to clear() and reinitialize()
functions.
- 2015-11-17: v2.33 - Minor bugfix for GCC versions < 5.
- 2015-11-2: v2.32 - Minor bugfix for non-trivial pointers and non-trivial
stack contents.
- 2015-10-31: v2.31 - Allocators which supply non-trivial pointers are now
supported. Large macros removed. Some code cleanup and minor performance
gain.
- 2015-10-10: v2.26 - 'back()' in plf::stack changed to 'top()' to better
reflect std:: library stack implementation function titles. Added standard
container typedefs to colony and stack. Colony iterators now return
element_allocator::pointer and element_allocator::reference instead of
value_type * and value_type &. Some minor code cleanup.
- 2015-10-6: v2.24 - Bugfix for C++03 with x64 compilers. Minor
corrections, performance improvements for C++03 compilers.
- 2015-10-4: v2.21 - Improved gcc x64 iteration. std::find now working with
reverse_iterator. reverse_iterator function corrections, performance
improvements. Hintless allocators under C++11 now supported. Allocation now
uses allocator_traits under C++11.
- 2015-9-30: v2.13 - Fixed performance regression with small primitive
types and MS VCC. Small bugfixes.
- 2015-9-28: v2.12 - Added const_iterator, const_reverse_iterator, .cbegin,
.cend, .crbegin, .crend. Some small bugfixes.
- 2015-9-27: v2.00 - Larger performance improvements, particularly for
small primitive type storage. Corrections to exception handling and EBCO.
".insert" replaces ".add" (realised there is precedence for
non-position-based insert via unordered_map/unordered_set). Added postfix
iterator increment and decrement. Zero-argument ".add()" and ".push()"
function overloads removed (same thing achievable with
"colony.insert(value_type());" and "stack.push(value_type());". Many
bugfixes and general code cleanup.
- 2015-9-15: v1.79 - Empty base class allocator optimisations and smaller
optimisation.
- 2015-9-1: v1.77 - Some small bugfixes.
- 2015-8-30: v1.76 - Now exception-safe. Also fixed C++03 regression
bug.
- 2015-8-22: v1.75 - Iterators more compliant and now work with std::find
and should work with other std:: algorithm functions. Native find functions
removed. (iterator - iterator) and (iterator + iterator) support added
(relatively useless to end-users, but required by some std::
algorithms).
- 2015-8-15: v1.73 - Correction to noexcept/nothrow use under some
non-c++11 compilers. Some rvalue functions corrected.
- 2015-8-3: v1.72 - Added noexcept to more functions.
- 2015-7-20: v1.71 - Small correction to demo, changed a data member name
in demo to remove conflict in MSVC 2015.
- 2015-7-13: v1.70 - Added deque comparisons to performance tests - this
was necessary because many people were making comparisons between colonies
and deques, without understanding what a deque is and how it
performs...
- 2015-6-21: v1.69 - Code tidy-up.
- 2015-6-16: v1.67 - Correction to VS2013/VS2010 support: move semantics
and other C++11 facets enabled for MS compilers. Support for VS2012, VS2015
and later added. Performance bottleneck in destructors in debug mode fixed.
General cleanup. Some microoptimisations. Macros now better named to avoid
conflicts.
- 2015-5-30: v1.60 - Correction to add function, microoptimizations.
- 2015-5-29: v1.53 - Performance improvement. Corrected move constructor
and reverse_iterator function semantics.
- 2015-5-28: v1.52 - Small correction.
- 2015-5-26: v1.51 - Small performance improvement. In demo, including
SDL.h caused some weird behaviour with timer when used, changed to
SDL_timer.h. Benchmarks to be updated.
- 2015-5-25: v1.50 - Microoptimizations, small improvements, fixed crash in
demo where memory would overflow when compiled to x86 without LAA.
- 2015-5-21: v1.43 - Minor performance improvements for release mode,
larger improvements for debug mode.
- 2015-5-16: v1.42 - Some demo corrections.
- 2015-5-16: v1.41 - Fixed demo on pre-C++11 compilers. Minor fixes in code
and corrections in tests. Performance improvements.
- 2015-5-11: v1.40 - Improved iterator ++ speed and Add speed, added
real-world OO performance tests to demo. Added max group-size tuning (max
number of elements per group).
- 2015-5-6: v1.34 - Improved iterator ++ speed under VC2010 and GCC
x64.
- 2015-5-5: v1.33 - Improved erase, and some small performance tweaks.
- 2015-5-4: v1.32 - Minor fixes.
- 2015-5-3: v1.31 - Resolved all current known edge-case crashes. Improved
stack pop performance.
- 2015-4-26: v1.20 - Found and resolved several edge-case bugs. Improved +,
-, += and -= iterator operator performance tremendously.
- 2015-4-18: v1.10 - Allocators fully supported now. Improved performance.
Some bugfixes. Added std::iterator trait to iterator. Added large struct
tests to demo. Improved realism of array tests.
- 2015-4-13: v1.00 - Allocators now largely supported (some work to do).
Erasure bug fixed. First proper release.
- 2015-4-9: v0.983 - Updated demo to be more realistic for array usage and
to run all tests sequentially.
- 2015-4-6: v0.982 - Bugfixes, speedup, added find functions.
- 2015-4-2: v0.98 - First release
Contact:
plf:: library and this page Copyright (c) 2025, Matthew Bentley