plf:: library and this page Copyright (c) 2026, Matthew Bentley.
Last updated 16-5-2026
Running mingw GCC 15.2 x64 as compiler. Build settings are "-DNDEBUG -O2 -s -std=c++23".
Full spreadsheet data is here.
For more general details and benchmark code see main page.
Click images or hover over to see results at linear scale instead



Click images or hover over to see results at linear scale instead



Click images or hover over to see results at linear scale instead



To summarize, for double on average hive is 28% slower for insert, 10% slower for erase and 8% faster for iteration.
For small structs it's 29% slower, 15% slower and 1% faster.
For large structs it's 38% slower, 26% slower and 16% faster.
Datatype is small struct (48 bytes), frame = one iteration pass over all elements in container.
Click images or hover over to see results at linear scale instead



plf::hive is 8% faster than hub on average.
Same as the previous test but here we erase/insert 1% of all elements per-frame instead of per 3600 frames, then once again increase the percentage to 5% then 10% per-frame. This simulates the use-case of continuously-changing data, for example video game bullets, decals, quadtree/octree nodes, cellular/atomic simulation or weather simulation.
Click images or hover over to see results at linear scale instead



plf::hive is 1% faster than hub on average for the 1% scenario, 4% slower for the 5% scenario, and 10% slower for the 10% scenario.
This test utilizes four instances of the same container type, each containing different element types:
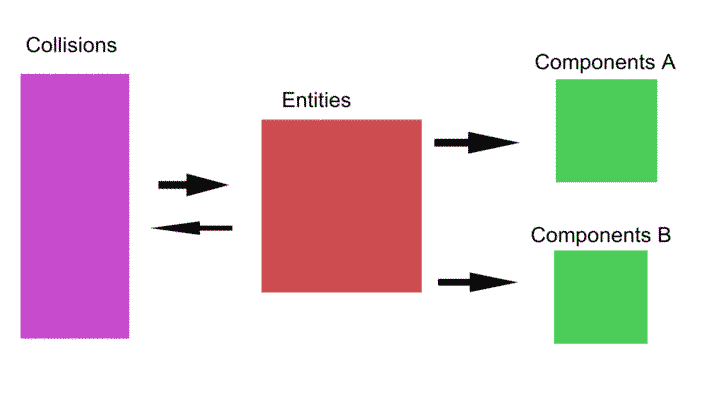
For full explanation see the main colony benchmarks page.
Click images or hover over to see results at linear scale instead






Average speed increase of hive over hub is between 2% and 406%, depending on insert/erase-to-iterate ratio, but with a massive skew in the larger numbers of elements. Up to 32x faster at highest ratio and number of elements.





Hive is generally slower than hub for insertion (except for large numbers of large structs) and erasure but faster for iteration. This is reflected in the 'real-world' benchmarks showing that with very high ratios of insert/erase-to-iteration (>= 5% of all elements in container inserted or erased per iteration over all elements) will be faster with hub under gcc, all lower ratios scenarios are faster with hive. Referencing between elements in multiple instances of the same container via pointers and erasing elements via those pointers on-the-fly is up to 32X slower with hub (2.4x average), due to a slower implementation of get_iterator(). Sorting is generally faster with hub except for large amounts of large structs, where hub gets 2x slower than hive.
Contact:
plf:: library and this page Copyright (c) 2026, Matthew Bentley.